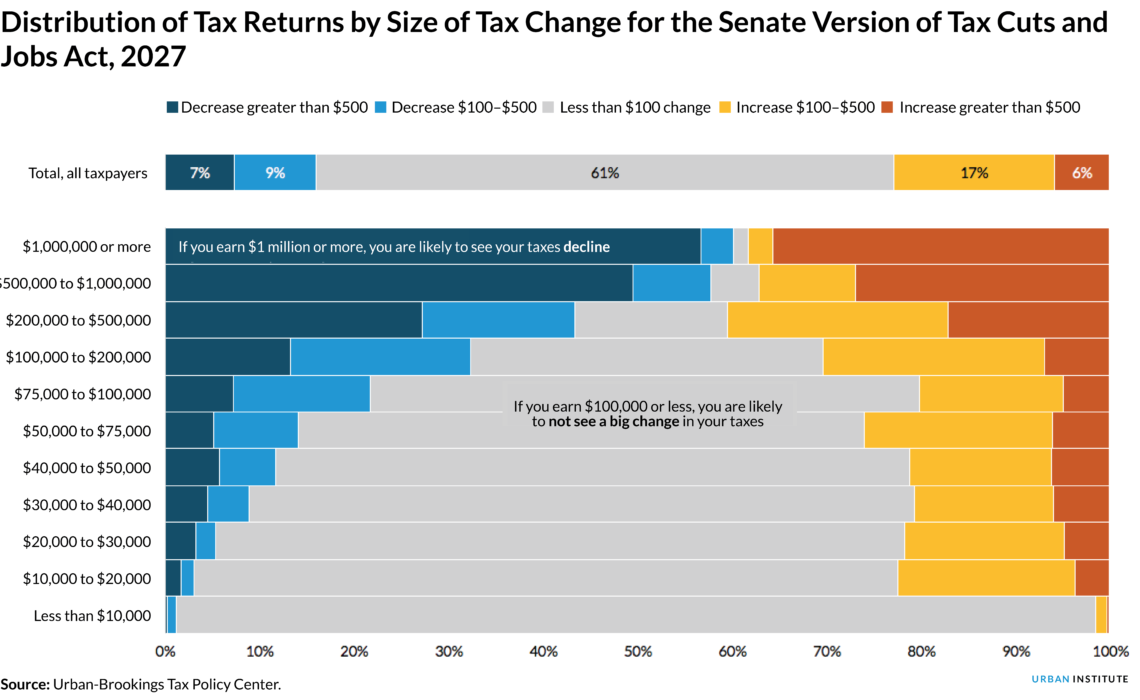
Over the past couple weeks, we’ve seen table after table presenting estimates of the impact of the tax reform legislation Congress is debating. Although these tables are useful, they are less engaging on my Twitter feed than, say, a graph would be.
So when I saw Michael Linden tweeted this table from the Joint Committee on Taxation (JCT), I thought I’d turn it into a graph to help people more easily see the important information it contained. The table showed analysis of the Senate’s version of the Tax Cuts and Jobs Act, not the version produced by the House and Senate conference committee, which is the final version under debate.
Many of my Twitter followers liked this graph, and it led to interesting discussions. Some discussions focused on policy questions (e.g., how to measure tax burdens, size of each group), but most others focused on the graph’s merits. I’d like to focus on these latter questions because they illuminate the important policy questions in a unique way.
Why did I visualize the year 2027?
My initial response was that I simply remade the original table from the JCT, which I found on Twitter. But upon further analysis of the original JCT report, I noted how different some of the other years in the report looked. I later made graphs for all five years the JCT published, like 2019, shown below.
2027 differs from the other years because the Senate bill sunsets all the individual income tax cuts while the corporate tax rate cuts and slower inflation indexing (an individual income tax increase) are permanent. Congress did this to satisfy Senate rules that prohibit deficit increases outside the 10-year budget window.
Congress is leaving it to future legislators to extend the individual tax reductions. This tactic—which both parties have used at times—creates uncertainty for individuals and businesses, and changes the incentives these different groups face.
Why didn’t I scale the income brackets by size?
The short answer is that the table in the original tweet didn’t have the bin sizes, and I wanted to make something and get it out the door. And although others scaled the brackets by size—including the New York Times—I’m not sold that this is a better approach because it obscures the results for the groups that have fewer tax units, namely those with very high and very low incomes.

It may be the case that less than 1 percent of tax units have more than $1 million of cash income, but I wanted to show that this group is also more likely to experience a tax cut than a tax increase. (I eventually did make something like this in Excel—a horizontal Marimekko chart—but I stopped short of publishing it for the reason above.)
Why show percentage with increases or decreases, rather than dollar amounts?
The JCT report did not estimate the dollar change in taxes for different income classes, only the percentage that would experience an increase or decrease within the groups shown in the graphs. That said, this is a valid critique. The dollar amounts are probably more meaningful. A tax cut of $100 for someone earning $10,000 is more in percentage terms than a cut of $5,000 for someone earnings $100,000. Further, readers will probably connect more with a graph that shows a rough estimate of their anticipated tax cut or increase than whether they are likely to be a “winner” or “loser.”
While JCT didn’t enable me to make these calculations, estimates from the Urban-Brookings Tax Policy Center (TPC) show that tax units at the bottom of the distribution are likely to see larger tax cuts in percentage terms than those at the top of the distribution.
Why do you trust the data?
Steve Wexler, a friend of mine in the data visualization field, raised this question, and my short answer (in a tweet) was that I used to work at the Congressional Budget Office (CBO) and knew many of the people at the JCT and trust their work. But it’s bigger than that. Wexler’s question made me think about what I see when reading estimates.
Let me start with this simple proposition: These numbers are not perfect forecasts (which don’t exist), but they are meaningful. There’s no way we’d make it to 2027 and find that the JCT’s estimates are spot on.
But we’re not asking the JCT to give us the truth from a crystal ball. We are asking for its best estimate of the truth given current information and what we can expect in the future.
The JCT is the official (tax) scorekeeper for Congress and, like CBO, is highly competent and scrupulously nonpartisan. The federal government invested taxpayer dollars to help design and implement models and estimates used to understand the economy and develop policy. Members of Congress on both sides of the aisle have alternatively praised and decried these and other agencies when their estimates agree or don’t agree with their policy proposals.
Trusted analysis is a vital check on federal policy and power
The JCT’s record also leads me to put faith in their numbers. In this case, the JCT’s estimates are in line with those of other independent organizations such as TPC and the Tax Foundation. These organizations are a check on federal agencies, so it’s vital to support and fund them.
As much as I respect the JCT’s work, I would appreciate more transparency with their models and data. I think CBO is better on this front because it publishes background and other papers about their models and budget estimates (full disclosure: in my nine years at CBO, my colleagues and I wrote several papers documenting the inner workings of the long-term Social Security model). The office also regularly evaluates the quality of its economic forecasts in publicly released reports.
I can’t tell you that numbers from the JCT, CBO, or similar agencies are correct. Similarly, I’m not going to tell you that football referees are going to get every call right. But the federal government named these agencies the official scorekeepers, or referees, of the budget and policy game for good reason.
This post was originally published on the Urban Institute’s blog, Urban Wire on December 18, 2017.