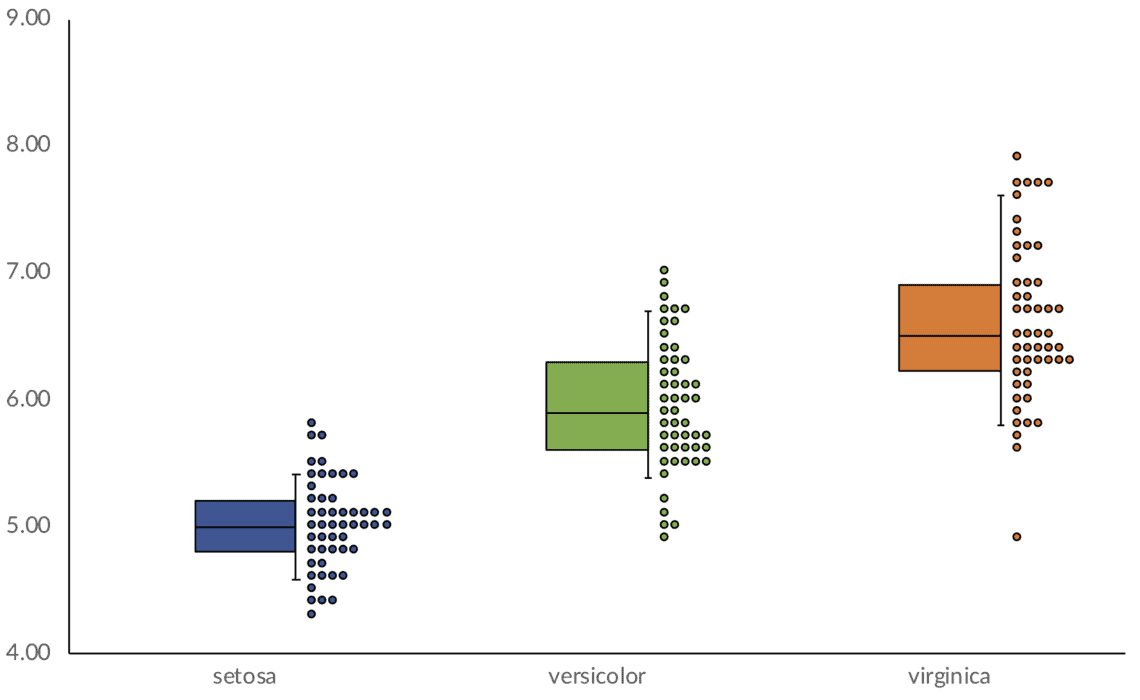
This graph popped up in my Twitter feed a few weeks ago. I have no idea what I’d call it—a box-and-whisker-and-scatterplot chart? I’m also not sure whether it’s better than a violin chart, which shows the entire distribution, but it’s certainly intriguing.
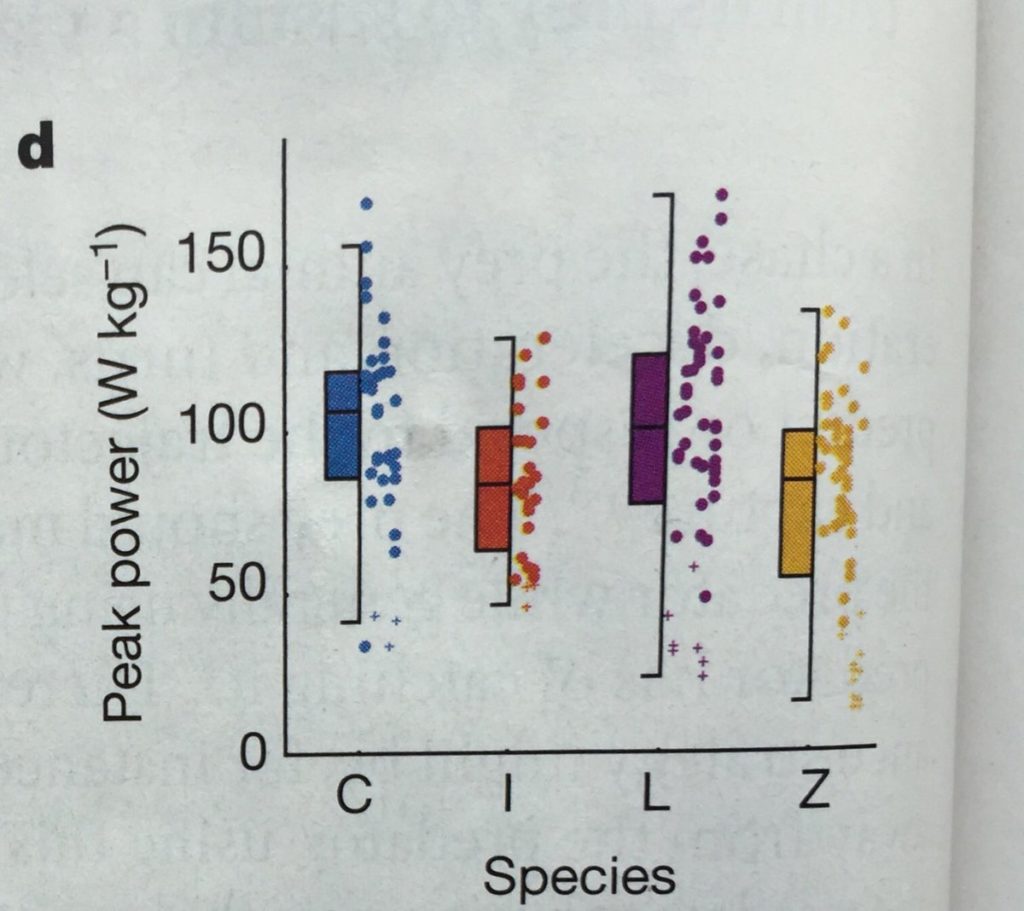
In my mind, visualizing distributions and uncertainty is a big data visualization challenge. It may be because many people simply don’t understand statistics and distributions, nor do they understand the mathematical concept of uncertainty and how it can be introduced into data and mathematical or statistical models. Perhaps the big issue about visualizing distributions and uncertainty, therefore, is that they require more significant annotation to help explain not just how to read the graph, but what is being graphed.
Anyways, I digress. I wanted to make this graph in Excel. I haven’t yet had a good excuse to try the new box-and-whisker chart type in Excel 2016, so I thought this was my chance. It turns out, however, that you can’t combine it with other chart types, so I had to use a different approach, one that combines three different elements:
- A stacked column chart for the box;
- A scatterplot for the whiskers; and
- A scatterplot for the data points.
As usual, I try to set up my Excel file so that this can be more easily replicated with other data later on. It takes a little longer to build the initial chart, but that will pay off with time savings later on.
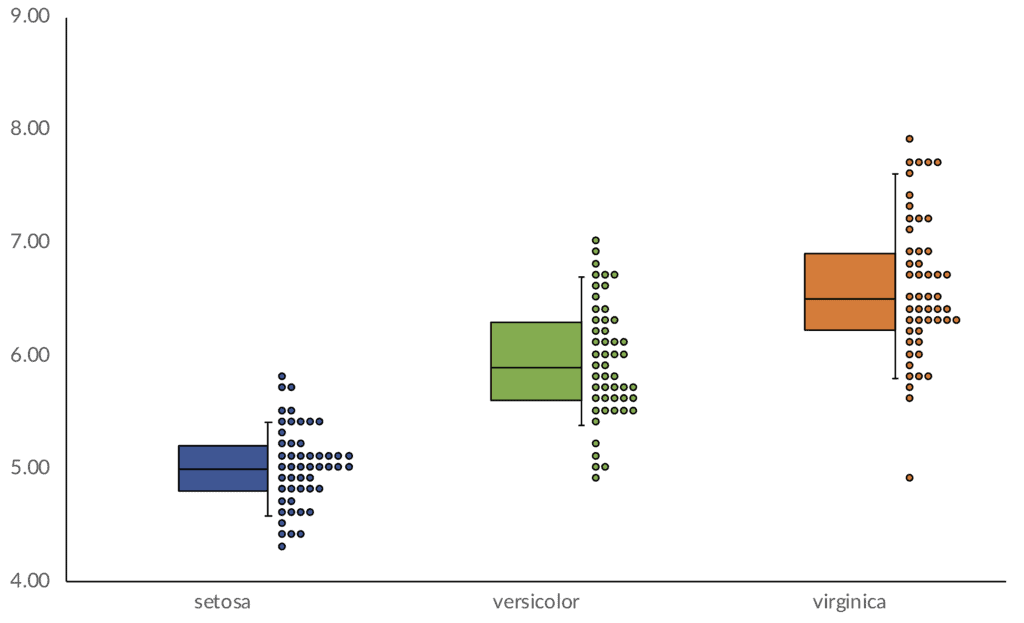
1. The stacked column chart
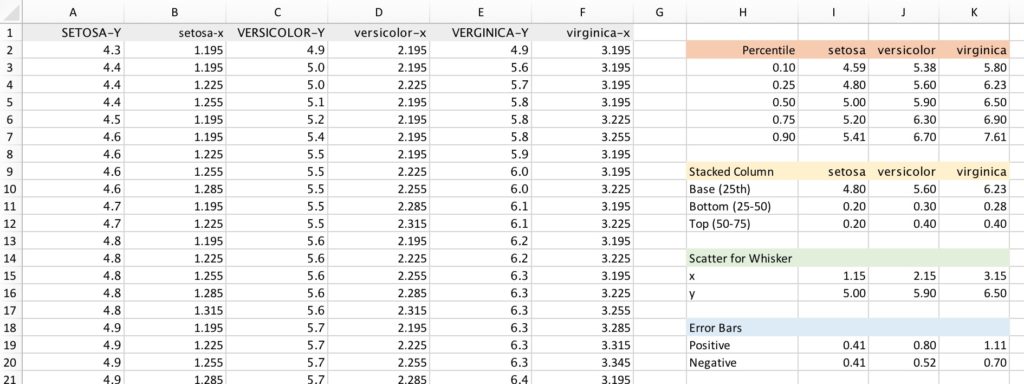
I’m going to calculate five percentile points from the data directly in Excel. This works here because I only have 50 observations; if I had a larger dataset, I would make these calculations in Stata or R and bring them over. The percentiles are calculated below the orange header row in the screenshots using the PERCENTILE formula. In cell I3, for example, I have:
=PERCENTILE($A$2:$A$51,H3)
This looks in the data column (A2:A51) and looks for the percentile point specified in cell H3.
In the yellow section below, I pull out the percentiles and generate differences I need to create the box. The bottom of the box in this chart shows the 25th percentile; the middle shows the median or 50th percentile; and the top shows the 75th percentile.
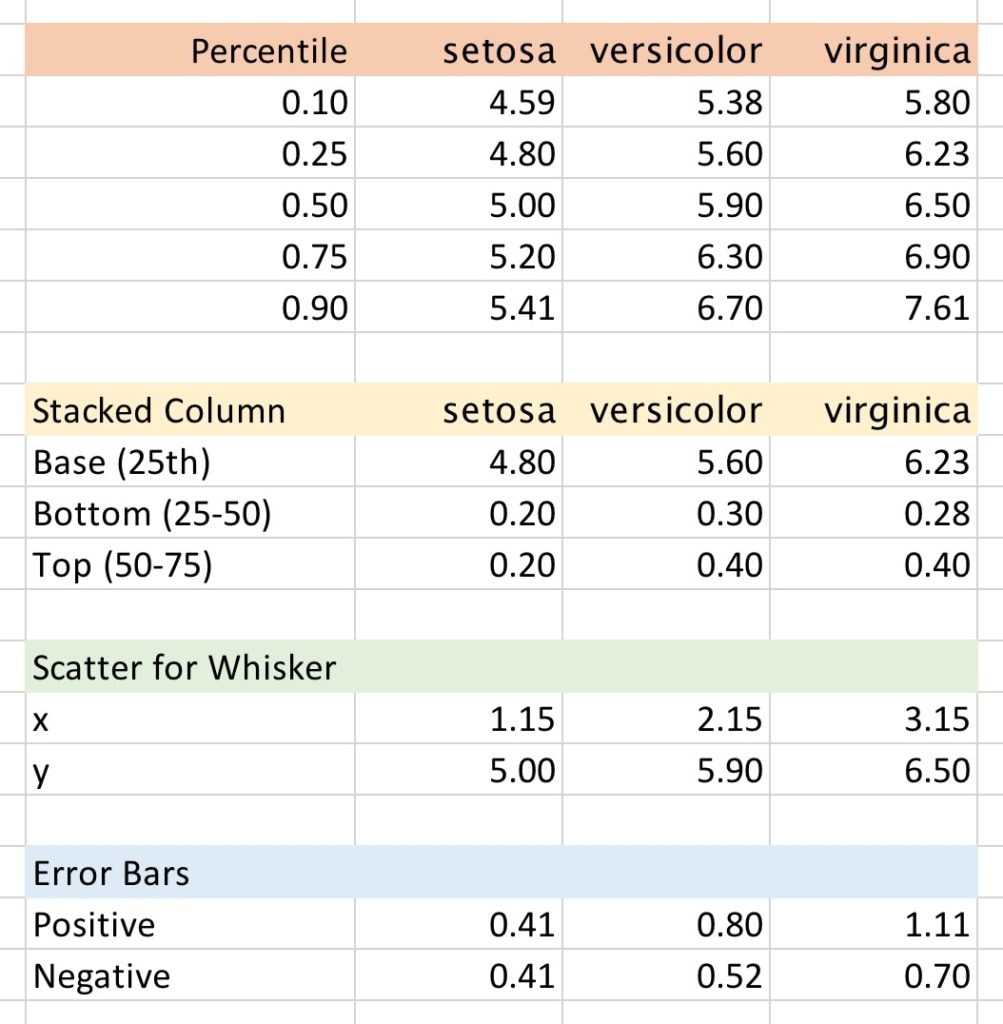
Thus, the bottom/base segment of the stacked column chart is simply the 25th percentile. I’ll plot it and then set the fill color to No Color. The second stack will be the difference between the 50th and 25th percentiles, and the third/top stack will be the difference between the 75th and 50th percentiles. To make it clear the middle of the box is the 50th percentile, I add an outline around both segments.
2. The scatterplot for the whiskers
To add the whiskers on the right edge of the boxes, I’m going to add a scatterplot point and then add a vertical error bar to denote the 10th and 90th percentiles. The scatterplots require x- and y- values, and are shown in the green section of the worksheet.
The y-values are simple—they are equal to the 50th percentile and thus the equation points to the original in the orange section above. For the x-values, I need to find the right-edge of each box, and while I’m sure there is some rule to how to find it, I experimented and it turned out to be 1.15, 2.15, and 3.15.
With the scatters plotted, I then added the error bars, the data for which are shown in the blue area. Because the whisker will reach up to the 90th percentile and down to the 10th percentile, the length of the lines will be equal to the differences between the median and those percentiles.
3. The scatterplot for the data points
The final element to plot is the dots representing the data. The data are shown in the gray area of the worksheet, with the original data in the columns with all capital letters. The actual data will be encoded to the y-axis of the chart, and they need to be assigned different x-axis values so they don’t sit on top of each other. Basically, the goal is to create a kind of unit-histogram of the data points and separate them enough to make them visible.
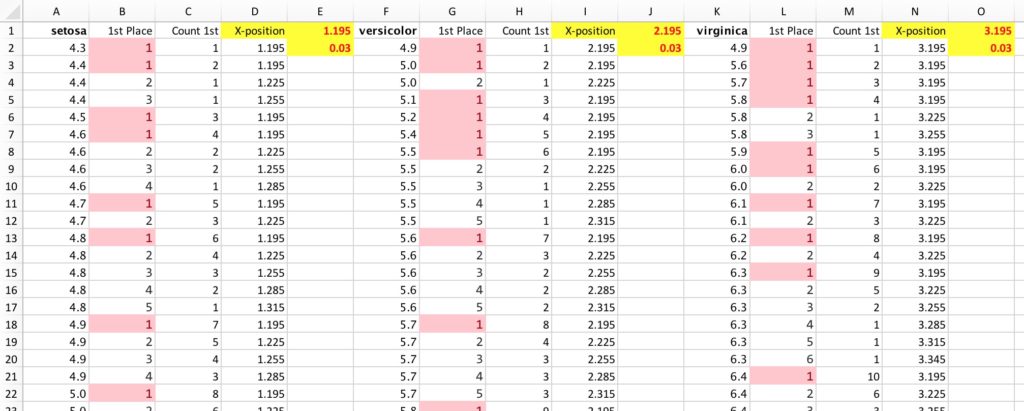
I set up the data in a different worksheet and start by sorting each separately (columns A, F, and L). (Again, if I had more data, I would probably do this in a coding environment and not in Excel). In the next column, I identify the first occurrence of each data “group”. In other words, I want to identify the first occurrence of the 4.3s, the first occurrence of the 4.4s, 4.5s, 4.6s, and so on. To do so, I use a simple COUNTIF formula and then layer on conditional formatting to highlight the 1s.
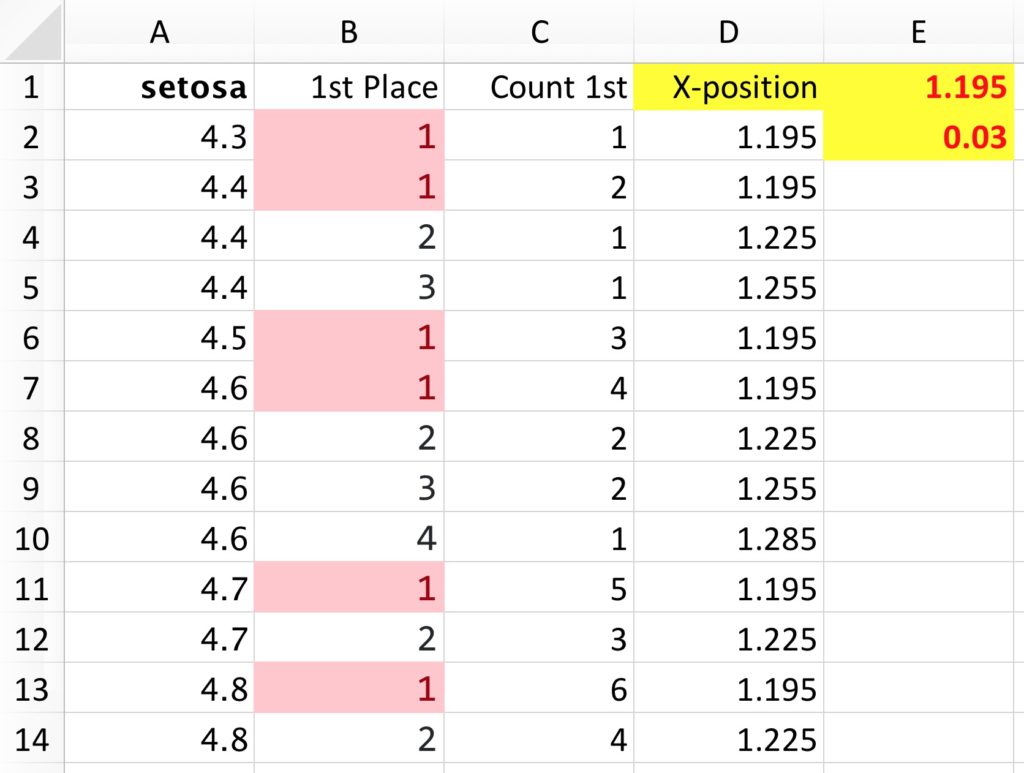
The COUNTIF counts the number of occurrences of the cell in column A by looking at the values from the top of the column down to the specific cell of interest. For example, the formula in cell B3 is =COUNTIF($A$2:A3,A3), which counts the number of times “4.4” shows up in just those two cells. Looking further down, the formula in cell B13—the first occurrence of 4.8—is =COUNTIF($A$2:A13,A13). (And, yes, by adding the absolute references—the dollar signs—to the first argument here, I can simply drag the formula down the column.)
The next column (C) uses the same kind of COUNTIF formula, but here to order the number of 1s in column B. In this way, I am essentially ordering the first observation of each group so that I can end up plotting them together along the x-axis. You can see the pattern in the screenshot above, counting 1 [4.3], 2 [4.4], 3 [4.5], 4 [4.6], and so on.
With the ordering set, I need to set up the x-axis values for each point. I start by first setting some fixed references. In cell E1, I set a value of 1.195, which is the position along the x-axis that is just to the right of the whisker. I chose this value because it looked like a good distance from the line, but I could have chosen something else. The 0.03 value in cell E2 is the horizontal distance between each dot. Other values could work, and I played around with some of them, but this worked for this chart.
We now pull it together and define the x-position of the scatterplot in column D. I use a little IF formula here to position the points to order or stack them. The formula in cell D2 is:
=IF(B2=1,$E$1,D1+$E$2)
So, if the data value is the first in the group, I assign it a value of 1.195—the point closest to the whisker. All of the data points that are first in each group will get this same value and will thus line up vertically in the chart.
For all subsequent points in each group, I add 0.03 to the previous value. Take a look at cell D10, for example, the 4th and last point in that group of values equal to 4.6. The x-value for that point is 1.195 + 0.03 + 0.03 + 0.03 = 1.285.
This whole data series is pulled back into my main worksheet and placed next to the original data points. I can now plot this as a scatterplot and am all set. I color and add an outline to match the box.
Concluding Remarks
I’m not sure if this is a better approach than a violin plot but calculating kernel density estimates in Excel is something I’m not tackling just yet. This graph approach—which combines the box-and-whisker with a plot of the actual data—has some nice appeal in that you get both the entire distribution and summary percentile points.
I don’t know how well it would work with more data, but for something small like this, I think it can work. Depending on the audience, it might require more annotation to help explain what each element represents and how to read it.
What do you think? A good chart type? Worth trying elsewhere?






Very cool! Did you overlay multiple charts, or were you able to do this in a single combo chart? I’ve been trying to do something similar and even though I have my data ready, I’m stumped about how to ultimately MAKE what you did from said data. I’d appreciate any insight you could share. Thanks!
Hi Gary,
I did this on one combo chart. The post explains the basics of how I set it up–the boxes are a stacked column chart and the dots are done with a scatterplot. I also added separate points with a vertical error bars to add the ‘whisker’. This post explains how I set up the data to create the scatterplot.
Thanks,
Jon
My co-worker and I are working for the hospital and was given a project to create a box plot with scatter plot.
They are 2 different datasets (one chart). Is it possible to create them together???? Thank you
Hi Maria,
I’m not entirely sure I understand what you mean, but as long as you arrange your data in the same Excel file, you could get them on the same chart. It’s a matter of correctly merging the two together. You can email me directly if you like, and I can take a look.
Thanks,
Jon
I am a doctor and working in the hospital.
I hope these will be helpful to you
https://tinyurl.com/Rain-Bowl-Plot
https://tinyurl.com/Cloud-Rain-Plot
https://tinyurl.com/dot-violin-box
Very interesting post and insightful
Could you upload the excel file? When learning I find it really helpful to have a file that I can interact with.
This method will not work with negative values.
I have wasted an hour this morning trying to avoid some R/Python/MATLAB-coding, thinking that there must be a way to use Excel to quickly generate a box-and-whiskers plot for returns data in the months following VaR breaches.
Excel has a built-in box-and-whiskers plot… but it assumes that columns are different variables in the same period (not the same variable in different periods).
The ‘calculate quartiles, diff them’ kludge only works for data where all quantities are positive.
Excel confirms my 25-year opinion that it’s little more than a toy, unfit for any data-science use worthy of the name (e.g., it doesn’t Bessel-correct covariance (or variance, I forget) calculations unless you specifically tell it to – even though it knows when it has relatively few observations)
Off I go back to R, Python or MATLAB. That’ll teach me for trying to use a toy to do a task that is ε away from ‘toy’.
Never again, Excel.
I keep saying that, but Excel does (most) toy tasks well: the problem arises when I mistakenly think “this is a toy task” and don’t close Excel the moment its built -ins don’t do the job.
A few things in response to your comment:
-Perhaps I’m misunderstanding what you are hoping to do, but this method works rather easily with negative numbers–see image. I just turned specific elements in the first series negative to illustrate; took me no more than 3 minutes.
-You make a common–and I think, ill-informed–conclusion about Excel. Like most tools, it is not suitable for everything. For example, I don’t recommend using Excel for regression analysis.
-There is, I think, an obvious schematic of tools here–Excel/Tableau and others are on one end that are primarily drop-and-drag. On the other end are programming languages like R/Python/Javascript. The Excel/Tableau end are limited by what you can do, but have lower barriers to entry. Programming languages give you more flexibility, but have a higher barrier to entry.
Thanks,
Jon
Attached image:
Hi Jon,
Thank you for the excellent explanation.
I have got the plot to work for either all positive or all negative values. However, I am having trouble with generating the stacked bars when I have both positive and negative values. Could you please explain how could I overcome this problem?
Regards,
Taimoor
Hey Jon,
I really appreciate thie DIY spreadsheet guide for box-whisker + scatterplot chart.
I have tried to follow three prong approach, but am having a problem in adding a scatterplot point for both the whisker and datapoints to my stacked column chart.
I can both create the stacked column chart and scatterplot seperately but not together. Would really apprecaite some guidance since it would look amazing combining the two.
thanks anton
Attached image:
I had trouble adding the scatterplot to the stacked column, so yesterday Jon and I had a Zoom to discuss my problem and HE solved it within 15 minutes. It was very helpful and Jon really helped me get through the last hurdle and now my data is presentable.
Many thanks to Jon and for shaving a bit of time out of his day to help me.
Anton
Attached image:
This is so cool!! Thank you for this detailed walkthrough. I was able to use the same concept and consolidate two graphs – a horizontal box and whisker (with the x and y axis flipped) and show the data points in the same chart as well. thank you again!!