A few years ago, I had a slew of meetings all in a row where different people kept asking me to help them make a map. “I have some state-level data,” they’d say, “can you help me make a map?” I’d ask: “Are you sure a map is the best way to visualize these data? What are you trying to show?” They would look at me, with spreadsheet in hand, look down slowly and reply, “I have state-level data.” Again, I’d ask, “Why a map?” One by one, they would give me a confused look and slowly respond, “Uh, because I have state-level data?”
And so it goes. People love maps. They are familiar, they are compact, and we know how to read them quickly and easily. There are, however, three primary issues with using maps to visualize data: First, the geographic size of an area may not correspond to its importance or value; second, population density may not correspond to importance or value; and third, our selection of break points can affect our perception of the data. In this post, I discuss the first two issues briefly and then dig into the third.
Map Issues
First, the size of a geographic unit may not correspond to the importance of the value being plotted. Russia, for example, is an immense country and even if the plotted values are smaller or less meaningful, it still takes up significant space on the map.
Note: Look how big Russia appears on this map of savings as a percent of GDP. Data from the World Bank.
Second, the population density of a geographic area may not correspond to its importance. Perhaps one of the more famous examples is this cartogram of the US electoral college system. In the electoral college system, each state is allotted a number of votes that corresponds to the number of residents. Not all states have the same number of people, so Montana and Wyoming, which are large states (e.g., square miles) with few people, appear much smaller in the cartogram, which sizes the states based on their population. Analogously, small but population-dense states like Connecticut and Rhode Island appear larger in the cartogram.
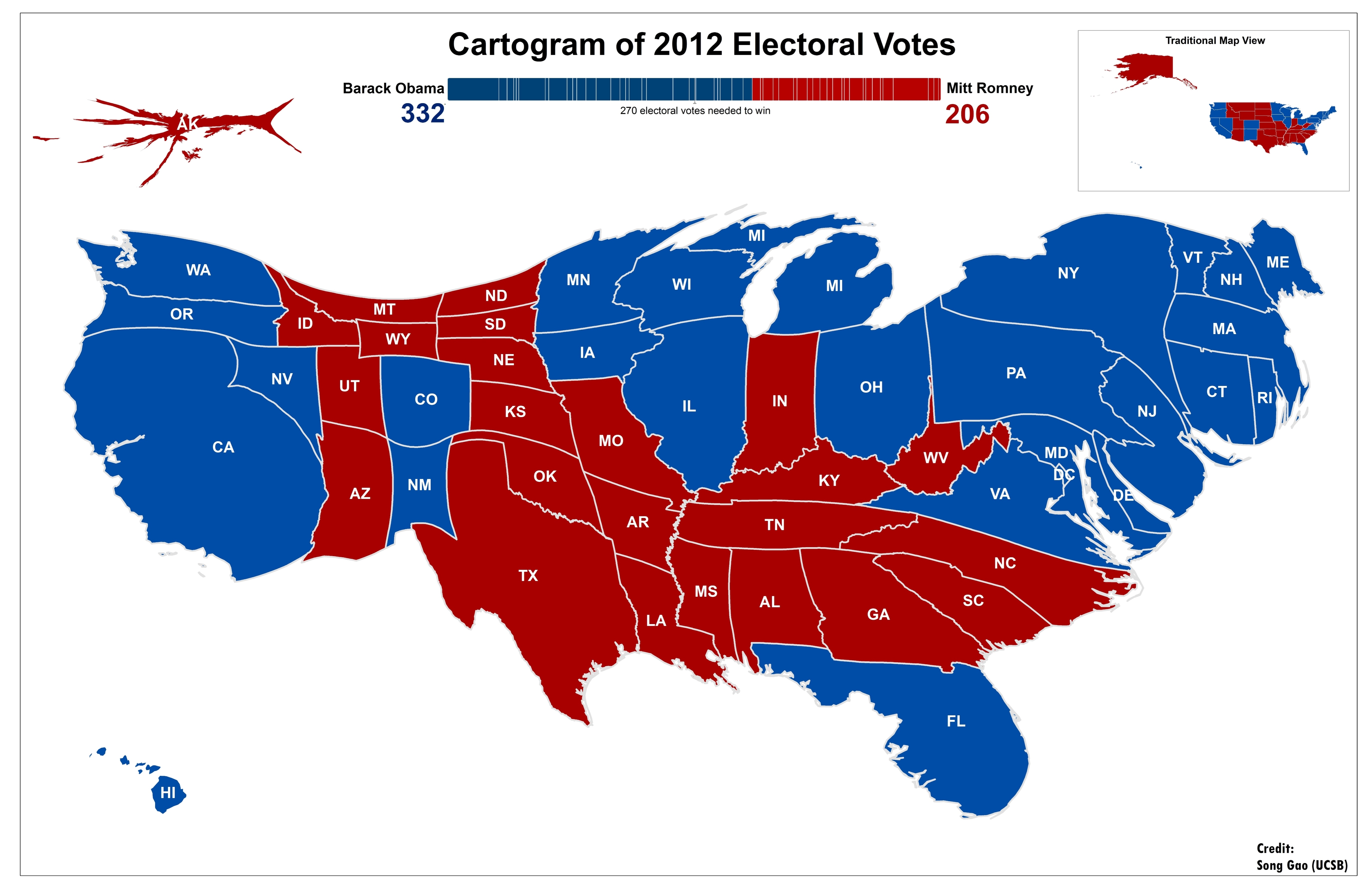
These geographic distortions can be addressed by using different graph types altogether, such as bars, columns, scatterplots, and slopes. People have devised other map presentations as well to address these geographic distortions, such as cartograms, tile grid maps, and hexagon maps. There is a trade-off however; addressing the geographic distortions by using one of these alternative map types makes the maps look less familiar.

Source: NPR Visuals Team
The third issue with your typical choropleth maps (and data maps in general, I suppose) are the breaks used to color the geographic units. It’s essentially an aggregation problem–some detail is going to be lost by placing observations into groups.
There are four primary binning methods one can use to create a data map, each with its own advantages and disadvantages.
- No Bins. This is essentially a continuous color ramp in which each data value receives its own gray tone. Using this subtle color gradient may generate spatial patterns that are masked by subtle changes in color. The No Bins model is the default approach in both Tableau and Infogram (and presumably other tools).
- Equal Interval Bins. In maps with a discrete number of bins, this approach divides the data range into n bins and places the geographic observations into those bins. For example, in a map with four bins and a data range of 1 to 100, we end up with four equal groups (1-25, 26-50, 51-75, and 76-100), though it’s not necessarily the case we would have an equal number of geographic units in each bin. (This is really just the special, discrete case of the No Bins category.)
- Data Distribution Bins. We could also cut the data into different bins; that is, instead of having n equal bins regardless of how many observations go in each (i.e., the Equal Interval Bin), we can have n bins that have the same number of observations in each, such as quartiles (4 groups), quintiles (5), or deciles (10). One could also use other statistical measures to group the data such as the variance or standard deviation.
- Arbitrary Bins. In this approach, the map producer chooses the bin cutoffs. They can be based on round numbers, natural breaks, or simply arbitrary.
The two discrete-binning models based on the number of bins and not the data (Equal or Arbitrary) may generate an uneven distribution of the number of observations. To illustrate, imagine a simple data set with 16 observations that range from 1 to 100 (95, 81, 80, 77, 74, 72, 70, 68, 66, 65, 58, 54, 28, 26, 20, and 18). Using the Equal Interval Bins method, we create four groups (1-25, 26-50, 51-75, and 76-100) and place the observations in each bin. This generates this rectangular “map” with 2 observations in the bottom bin, 2 in the second, 8 in the third, and 4 observations in the top.

If we were to use a Data Distribution Bins approach and divide the data into quartiles (4 groups), that same “map” looks quite different.

Also notice how the aggregation problem is clearly evident in both maps. It’s not obvious that the two observations in the top bin have values of 95 and 81, nor is the magnitude of that difference clear. Similarly, even though the fourth and fifth observations are in two different groups (in both maps), using color to encode the data doesn’t enable us to visually see the (relatively small) difference between the two values as we could in, say, a bar chart:
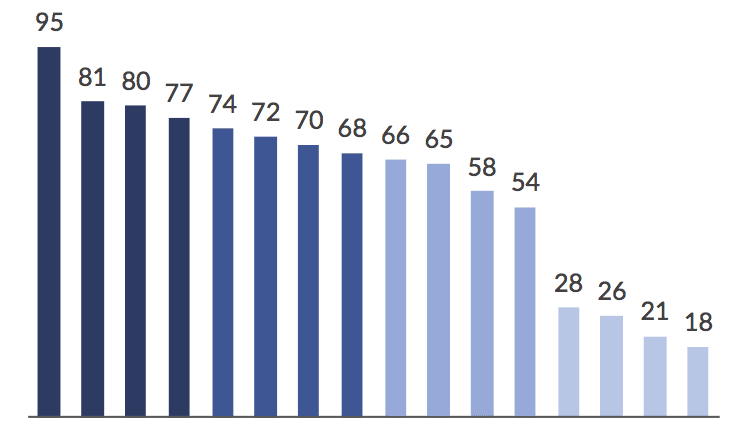
In this representation of the data split into 4 groups, you can clearly see the difference between the first and second values, even though they appear in the same bin in the map. You can also see the relatively smaller difference between the fourth (77) and fifth (74) observations, even though they are in two different bins.
A Real Example
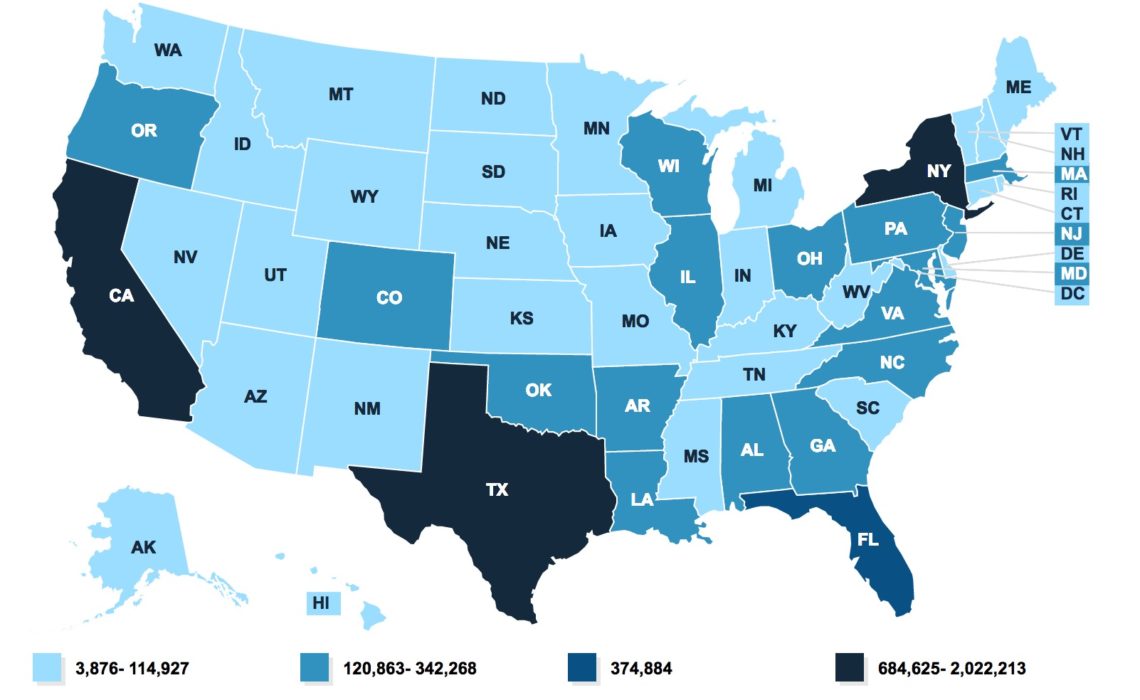
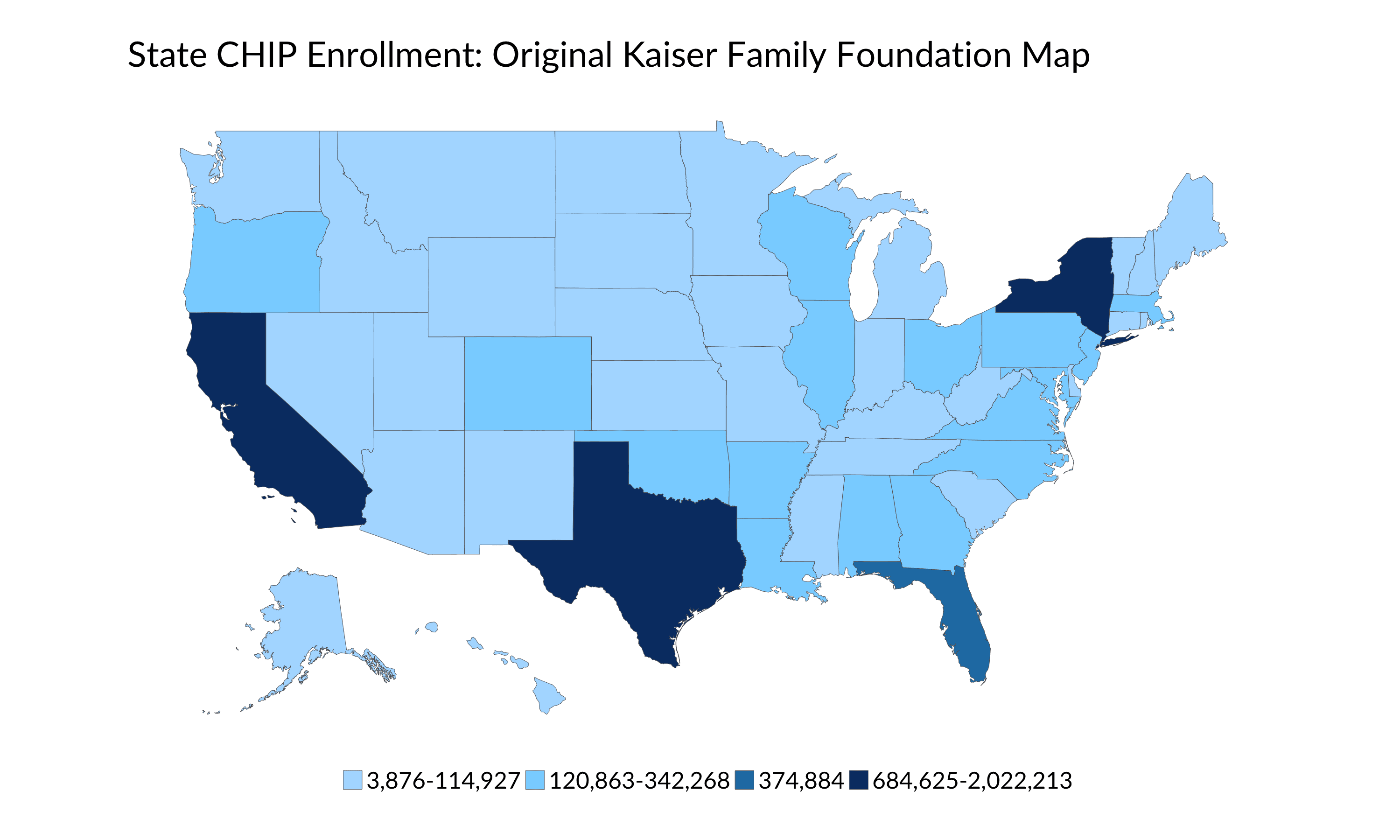
I want to dive into the act of choosing the bins more deeply using actual data. To illustrate, I’m going to use this state-level map of Children’s Health Insurance Program (CHIP) enrollment the Kaiser Family Foundation published a few weeks ago. The original map has four bins, each with a different number of states:
- 3 states (California, New York, and Texas): 684,625-2,022,213
- 1 state (Florida): 374,884
- 16 states: 120,885-342,268
- 31 states (including Washington, DC): 3,876-114,927
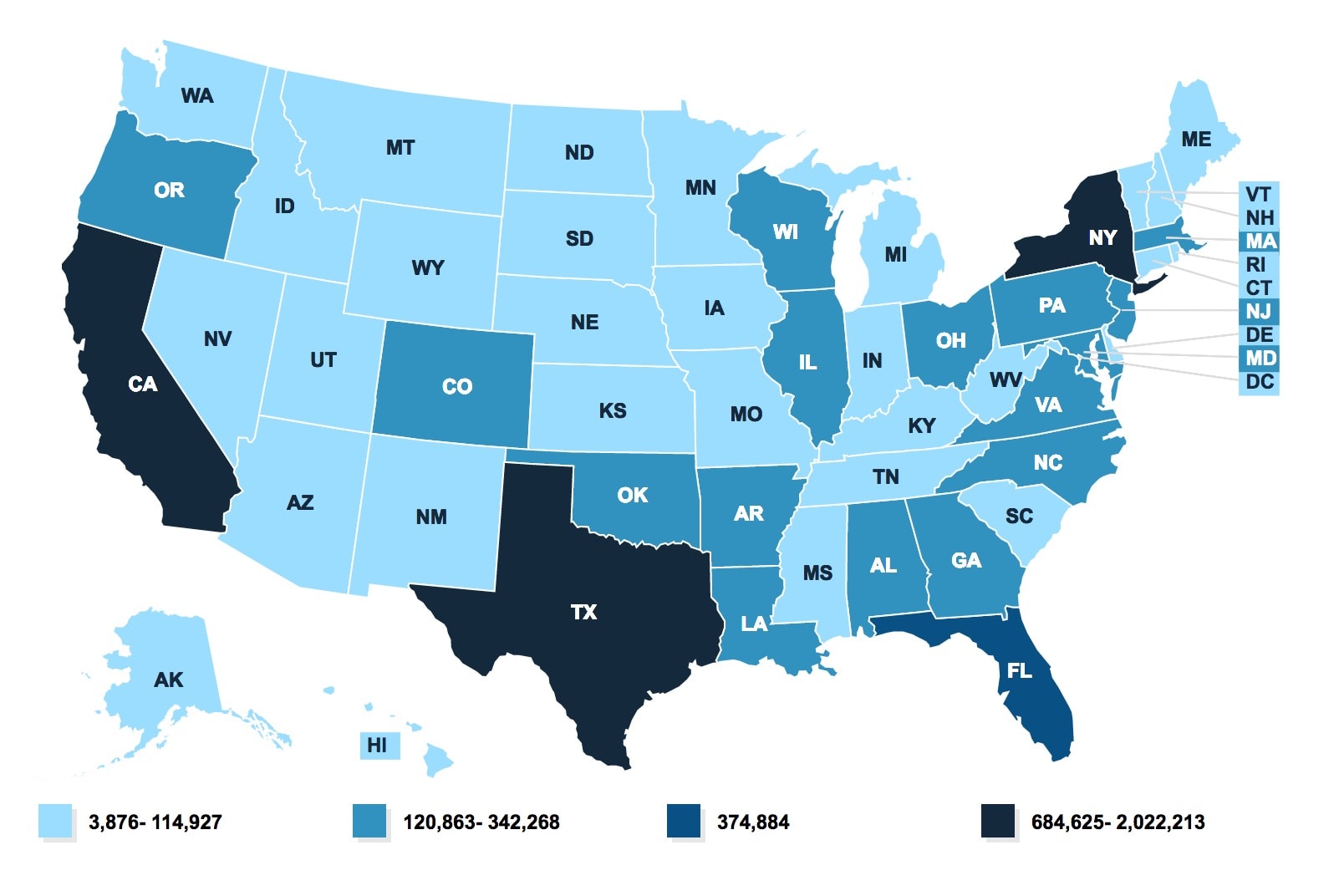
Source: Kaiser Family Foundation
Notice the uneven breaks and the gaps between each. Those gaps correspond to the actual values in the distribution, but it’s not immediately intuitive from the map. I’m not arguing this binning decision is wrong (though maybe a bit odd) only to point out that the creator made a decision to use these specific bins.
Let’s look at these data more closely in a column chart, sorted and colored in the four categories.
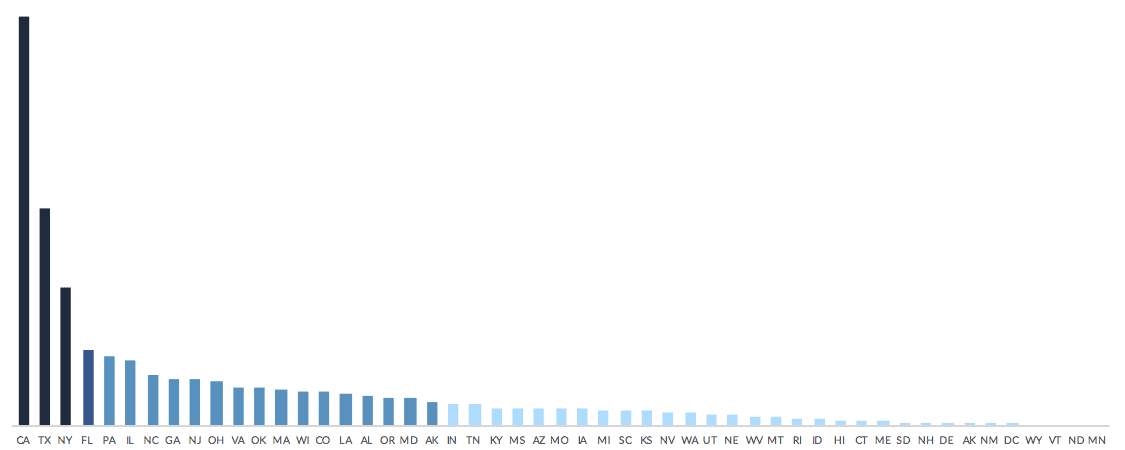
What becomes clearly evident here is that CHIP enrollment in the top three states—California, Texas, and New York—are clearly and significantly larger than the rest of the country (yes, I recognize these data are not per capita and are therefore largely proportional to population, but bear with me, I’m using this as an illustration).
It’s also interesting that Florida (374,884) is placed in its own category in the 4th position, even though the number of kids on CHIP in Florida is not that much larger than the next two states, Pennsylvania (342,268) and Illinois (325,990). (It’s possible KFF’s binning decision is content-driven and for some reason Florida should stand out on its own, but there’s no explanation on the Kaiser website.)
Let’s see what happens when we make different decisions about the bin cutoffs.
In this version of the map, I’m still using an Arbitrary Binning approach but I’ve grouped Florida, Pennsylvania, and Illinois together, and then split the rest of the country into two nearly-identical groups of 23 states and 22 states (which has the coincidental effect of creating a cutoff at the round number of 80,000). The resulting shift of 11 states from one category to another—both reasonable selections to define the bins—changes the entire look of the map.
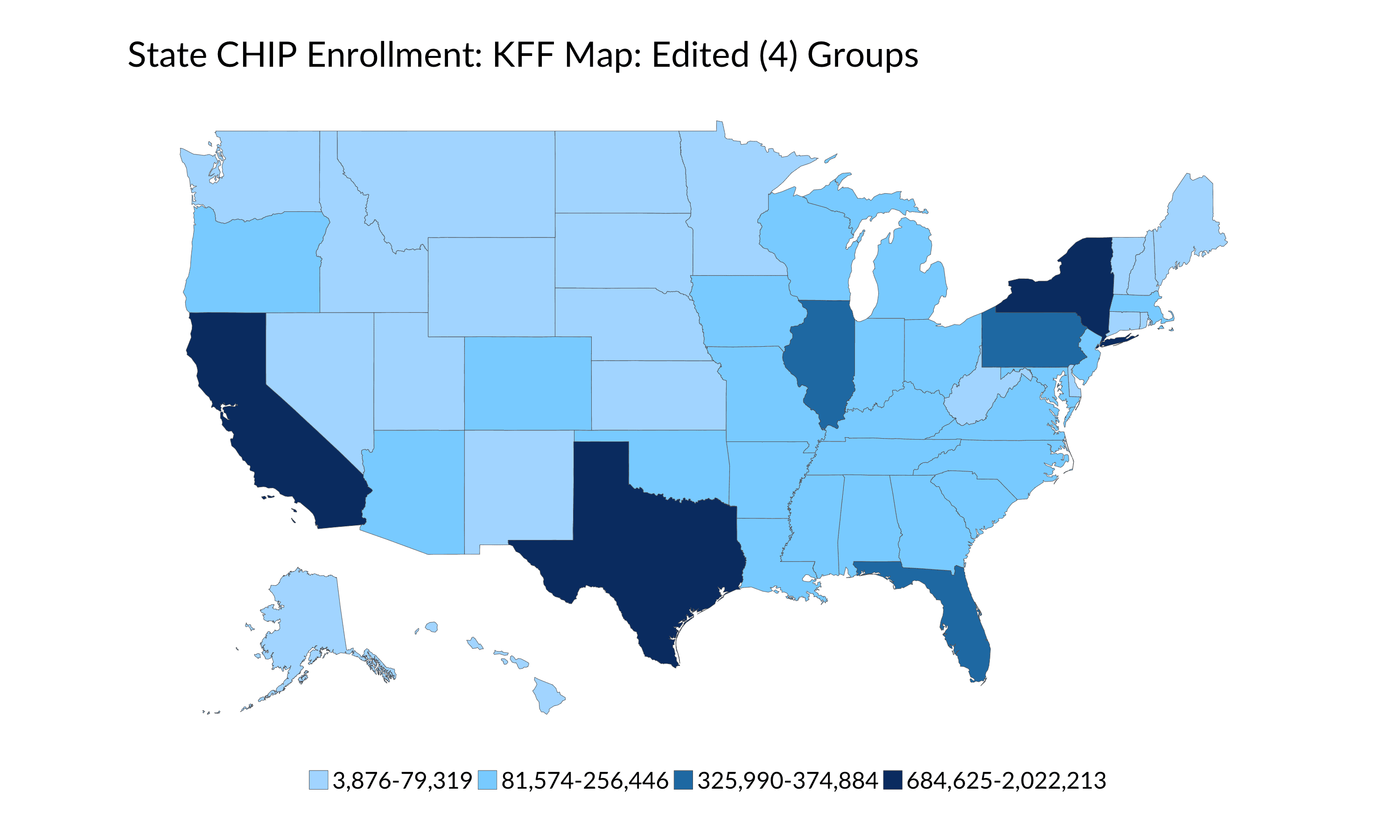
You might also notice that I’ve defined the bins based on the actual data values instead of rounding them (for example, the first bin could be 0-80,000 and the second bin 80,001-300,000). This is another choice we make when we produce a map, but is a bit beyond this (already long) post.
Using Percentage Change to Help Choose the Bins
Selecting the cutoffs in the Arbitrary Bin model might be decided by looking at the differences between adjacent observations when the data are sorted in order. That can be accomplished by looking at the percentage change between the ranked states (in the Tableau figure below, the first entry in the right bar chart is the percent change in CHIP enrollment between California and Texas). In this view, the percentage differences between Florida and Pennsylvania (9.5%), and Pennsylvania and Illinois (5.0%) are relatively similar, while the difference between the next two states, Illinois and North Carolina, is a much larger 27%.
At this point, I draw on something I learned from Mark Monmonier’s book, How to Lie with Maps and my conversation with him on The PolicyViz Podcast: Instead of using equally-sized bins arbitrarily or letting the software tool decide for you which breaks to use, look at—and also show—the actual distribution.
The two bar graphs that pair levels with percentage change help me determine different breaks and explore the different maps under these different binning choices. Let’s look at what happens to the original Kaiser map when we use five groups instead of four: Keeping the top 3 states together makes sense (though one could easily argue each should be in their own group), and then grouping the next 3 states (Florida, Pennsylvania, and Illinois) as before. From there, I might edit the original groupings just slightly—my 3rd group would go from North Carolina (256,446) to Maryland (137,592), moving Arkansas (120,863) to the 4th group.
For the 4th and 5th groups, I could simply split the remaining states—there are 32 overall—into two equal groups, breaking it at West Virginia. This would potentially work, because there’s also a round break point at 50,000. There are some other possible breaks within this group, for example at Hawaii (essentially a break at 30,000) and Wyoming (a break at 10,000). Here’s the original map now broken into 5 groups:
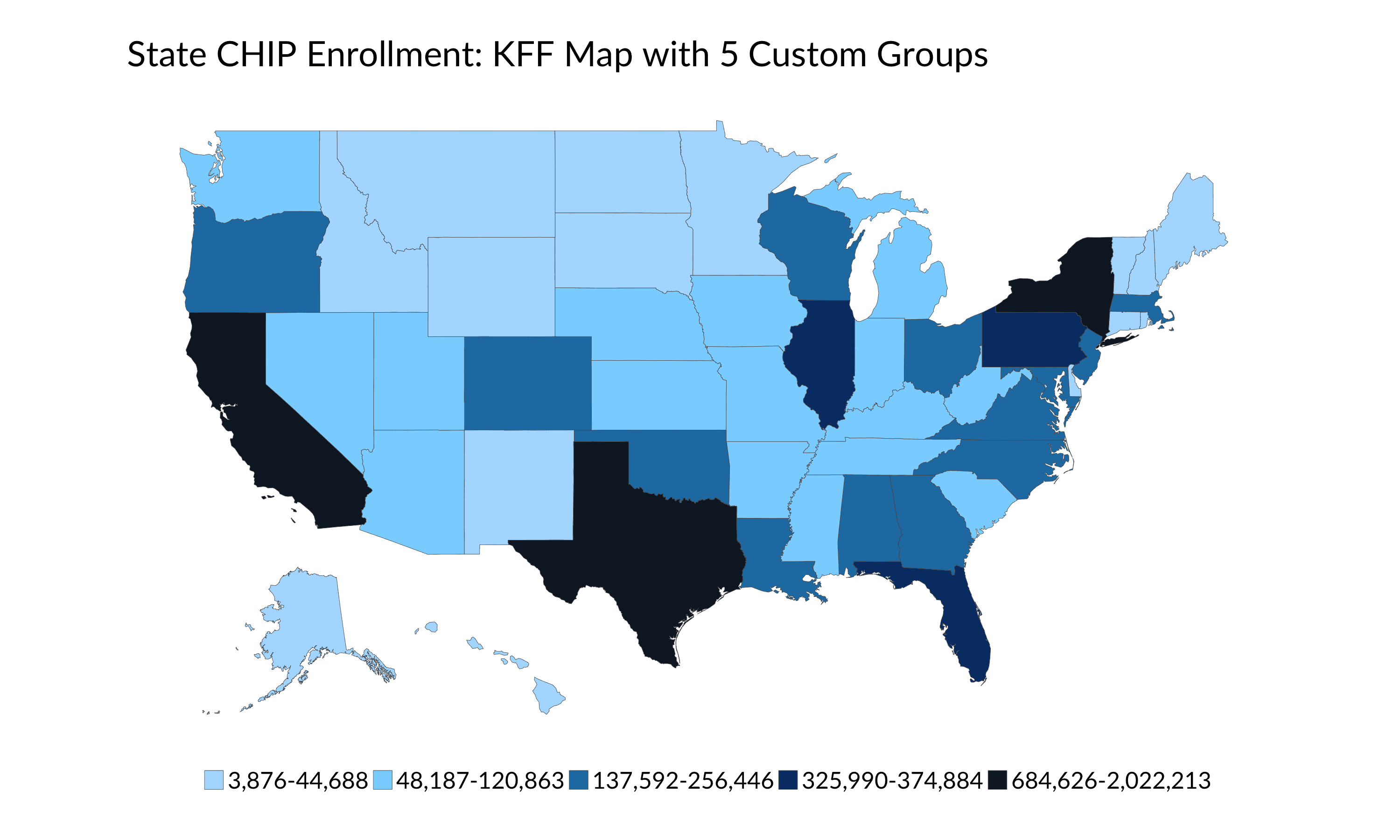
There are a lot of other choices I could have made here: breaking into n-equally-sized bins (well, nearly equal because there are 51 observations) as in Tableau, for example, or choosing round break points of above 200,000 (10 states), 100,000-200,000 (12 states), 50,000-100,000 (12 states), 25,000-50,000 (6 states), and below 25,000 (11 states). Or, I could use the Data Distribution Bins approach and split the data into quintiles. Look what happens when I plot these data using these different groupings.
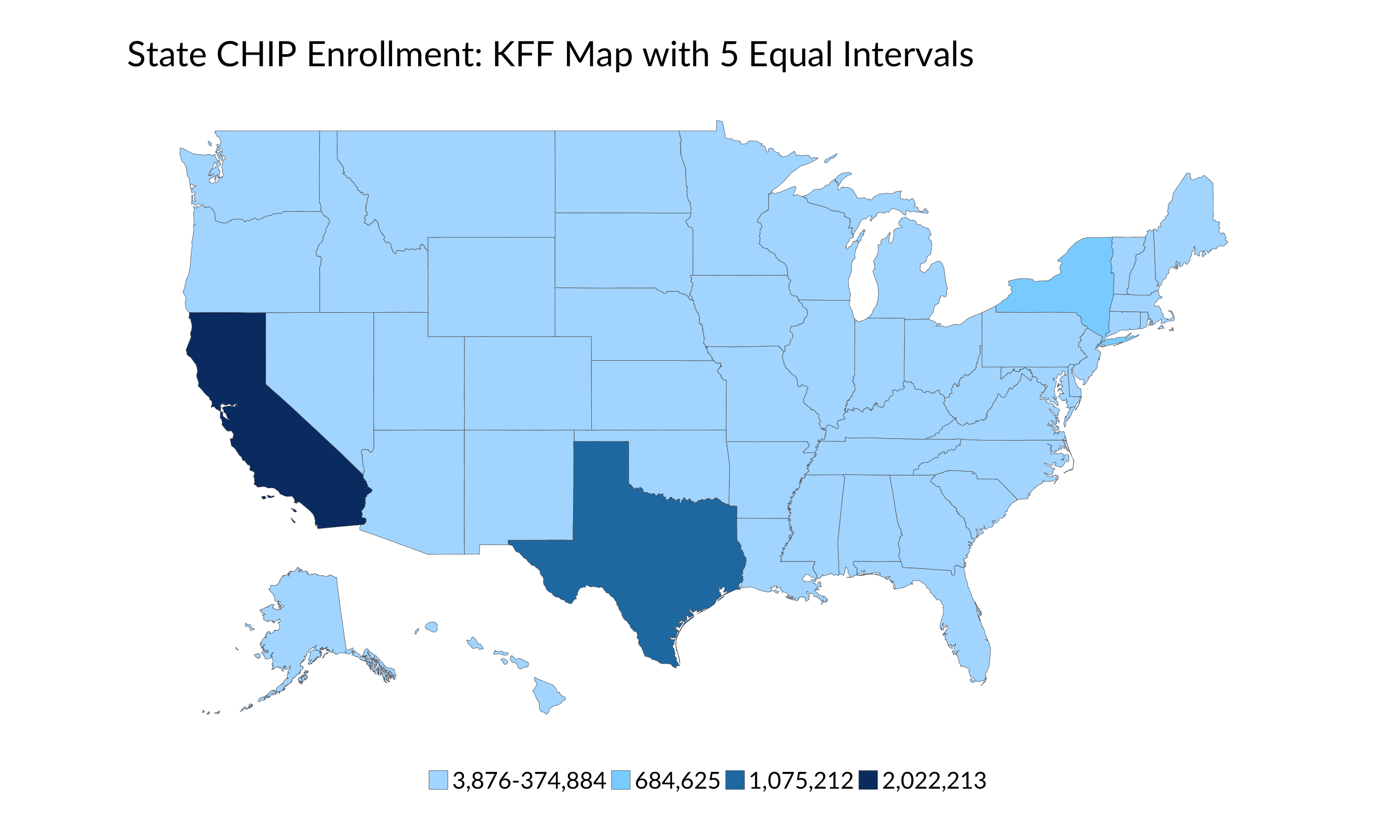
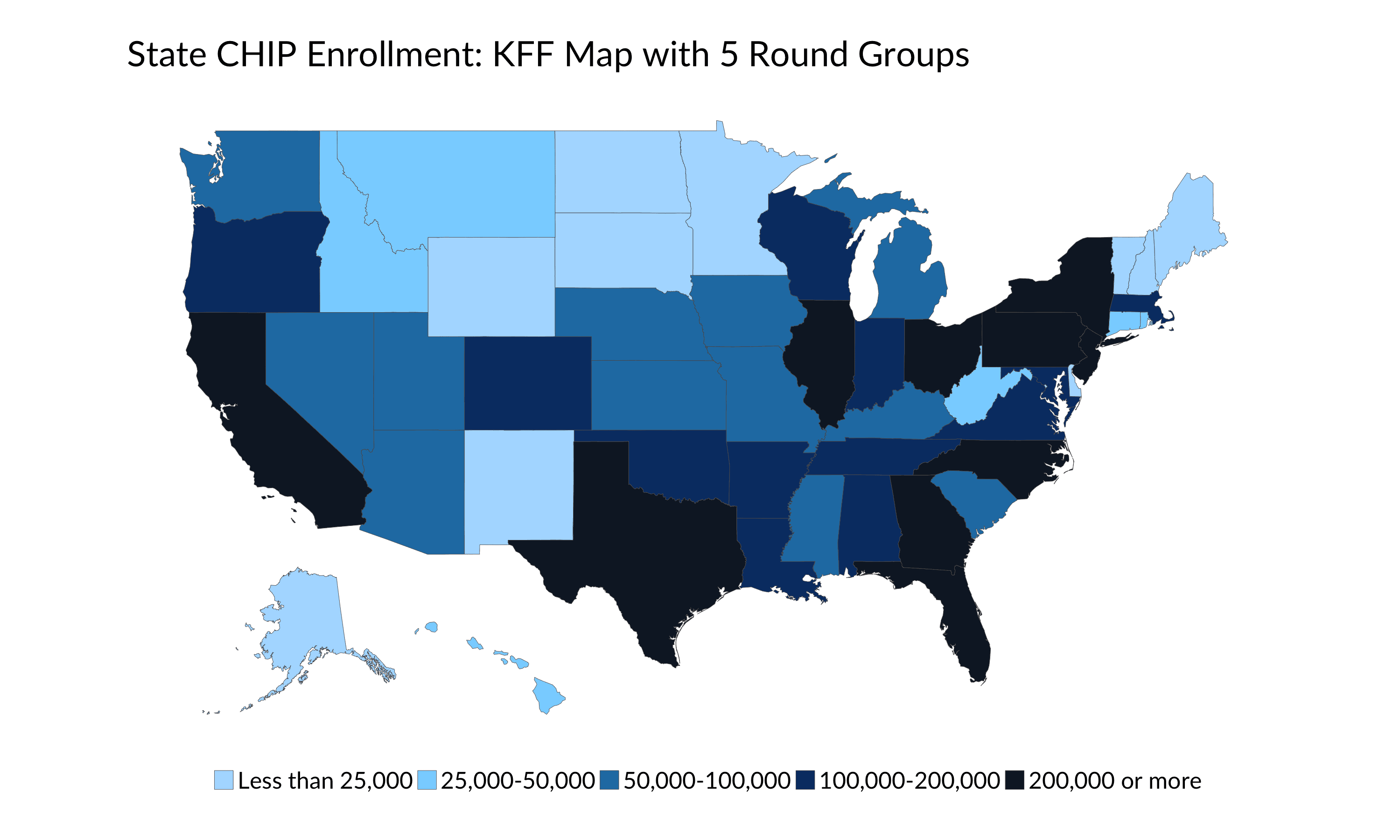
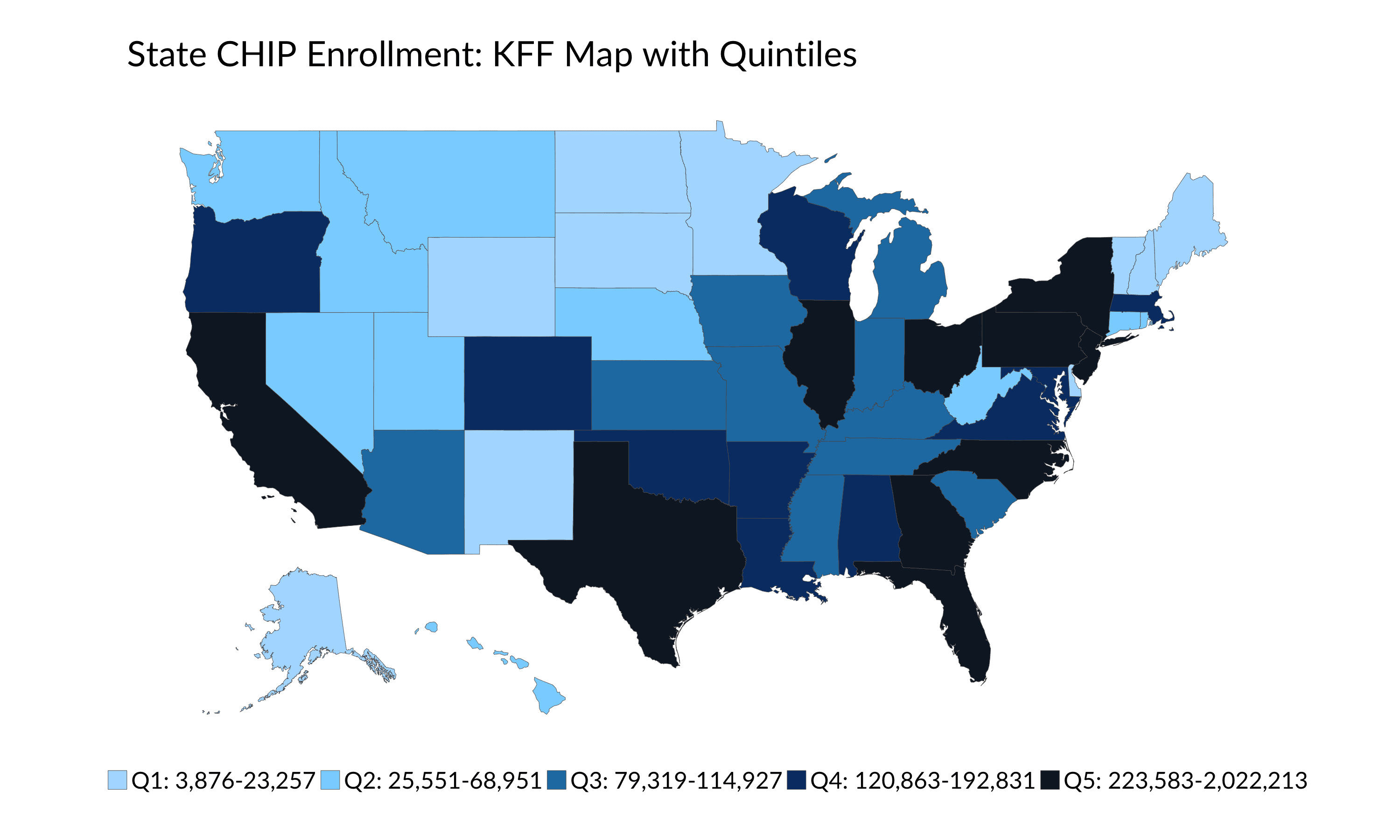
We could also try a No Bins default map that can be easily created in Tableau and other tools. Notice how California, Texas, and New York essentially get their own distinct shades of blue, while much of the rest of the country become nearly indistinguishable.

This isn’t to say any of these maps are right or wrong, but to point out how important the binning decision is in making a choropleth map.
A Census Bureau Example
Let me show you one more example. Here’s a map from the US Census Bureau showing median household income in 2016. Notice the four breaks: <$45,000 (3 states), $45,000-$49,999 (7 states), $50,000-$59,999 (22 states), and $60,000 or more (19 states). There is no explanation in the text about why these particular breaks were chosen, and one could argue that it makes complete sense to highlight the 3 states with the lowest incomes (Arkansas, West Virginia, and Mississippi).
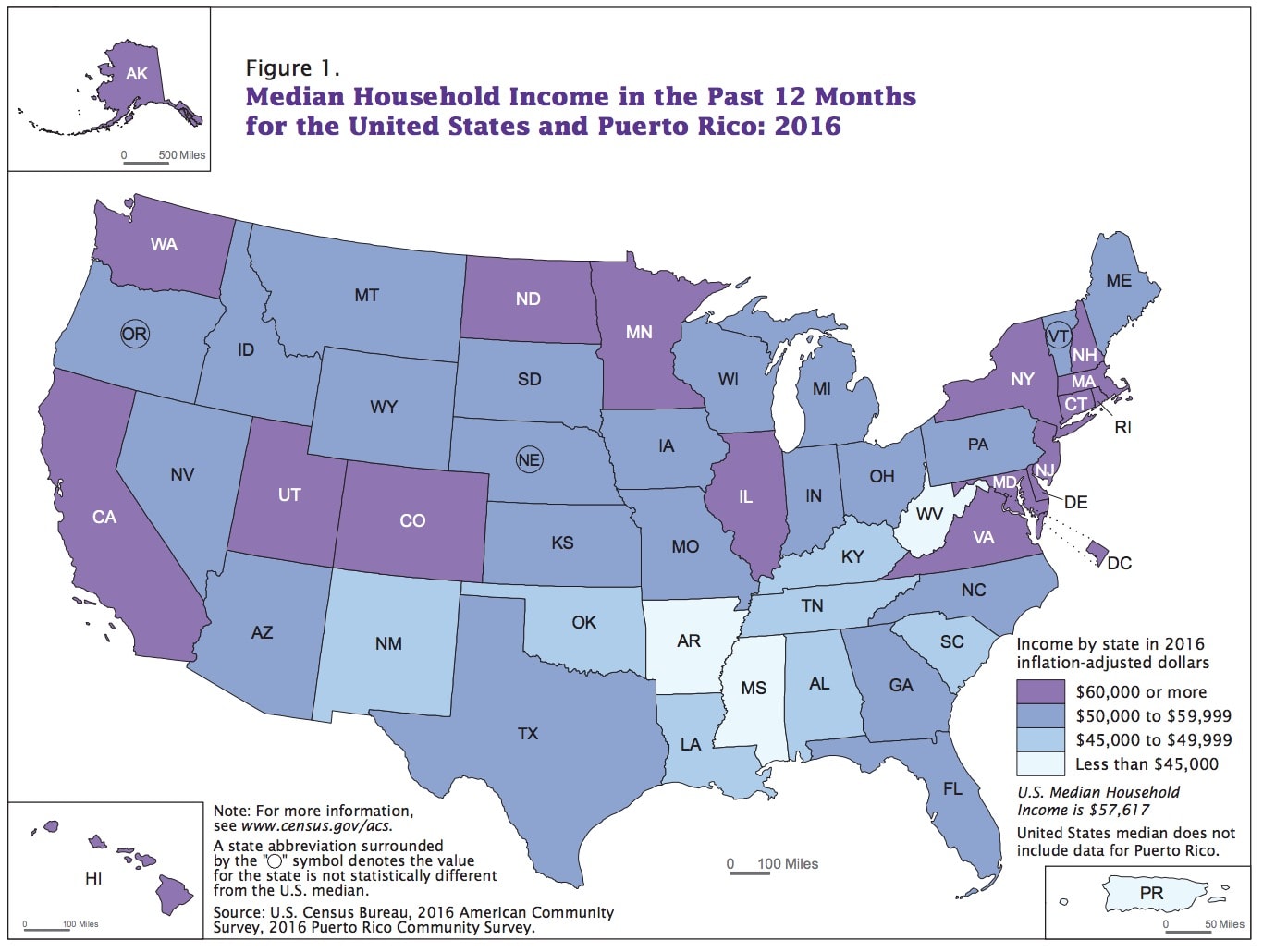
Source: US Census Bureau
Instead, let’s start with the standard approach of breaking the distribution into four bins and dropping the states into each (the Equal Interval Bins approach). Under this different approach, 40 states change category, resulting in a very different–and less purple–map.

We can also try the Data Distribution Bin approach and divide the data into quartiles (three groups of 12 and one group of 13). Here, 13 states change categories from the Equal Interval approach.
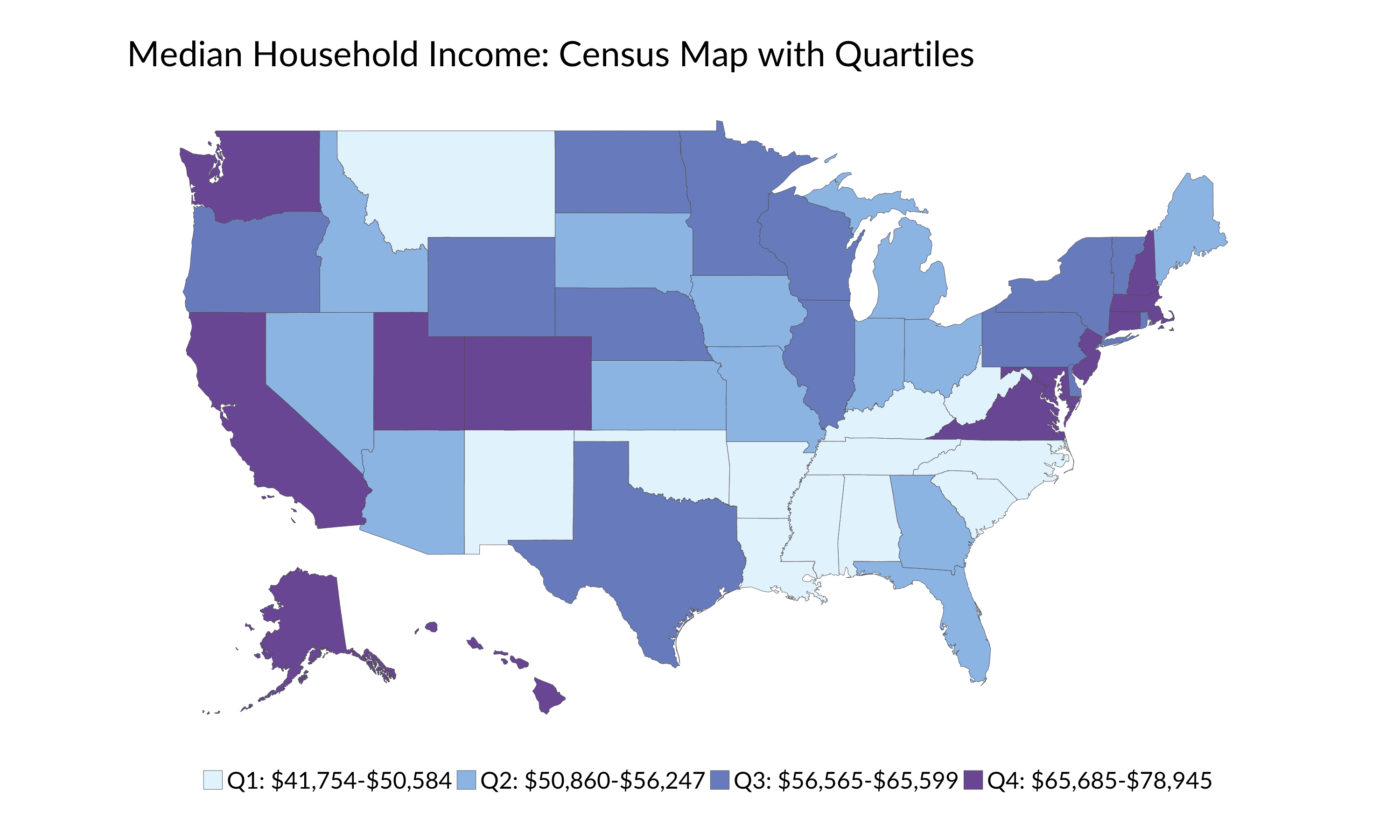
Using either of these binning approaches is also debatable because some of the breaks don’t make much sense. In the equal-sized bin groups, for example, Colorado ends up in the first group with a median income of $65,685, while Minnesota, with a median income of only slightly lower at $65,599, goes into the second group. But those cutoffs are bound to happen, especially in continuous data sets.
What to do
I’m not arguing any of these choices are “right” or “wrong”. There may be perfectly legitimate reasons to choose one binning method over another. I think it’s clear that our perception of geographic data can change because of how we decide to group the observations.
So, what to do? First, don’t let your data visualization tool—whatever it may be—choose your map bins for you. Be selective and be purposeful. Second, show the data in multiple views. Drop a column chart below the map or a bar chart next to it, as I show below with the original Census map. You might also show a histogram below the data, as NPR did in this story on school district spending in the US.
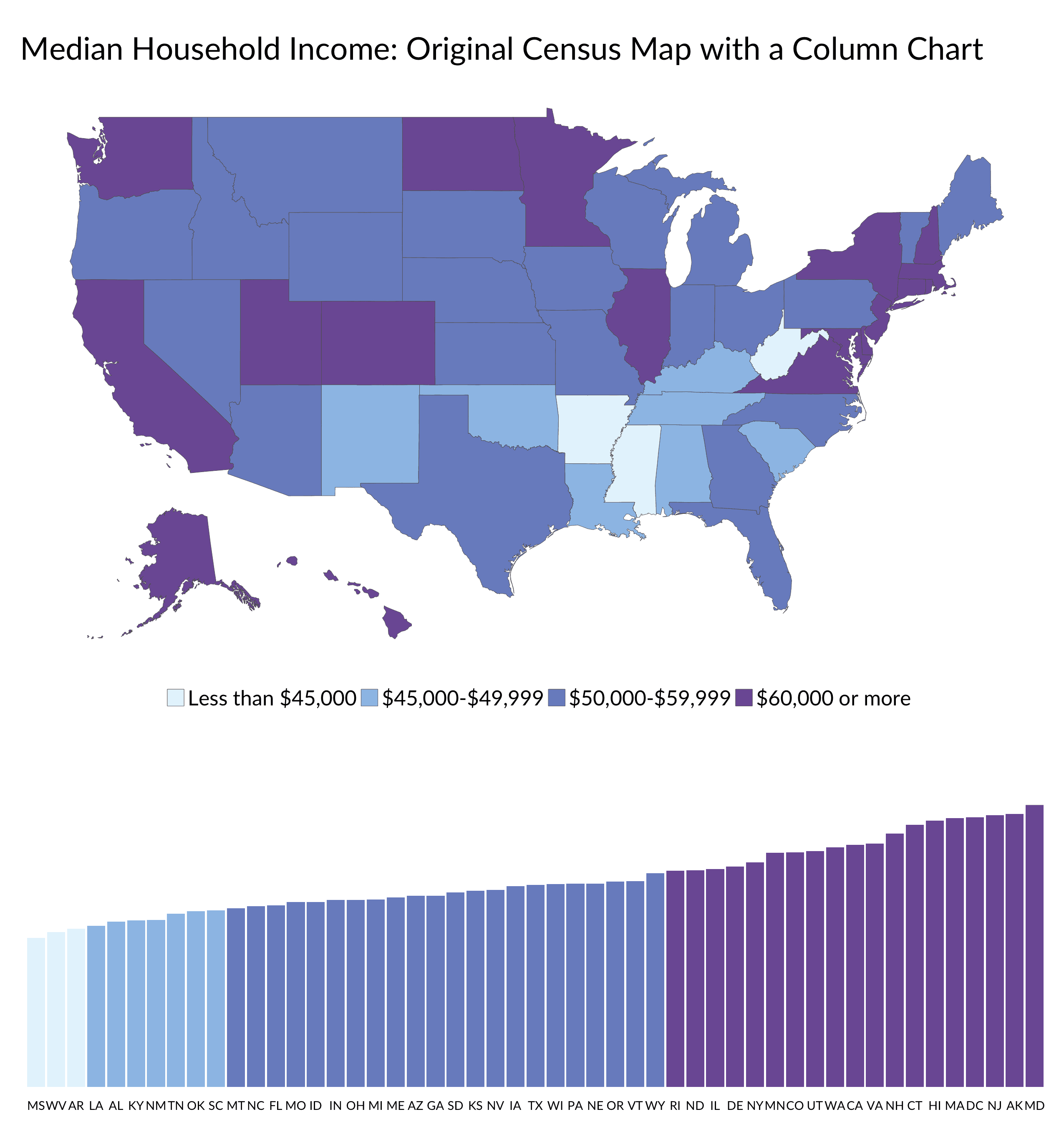
Another alternative is to include the number of observations in each bin. As an example, the Urban Institute’s State Economic Monitor includes interactive maps and column charts so that the user gets both views. I could edit the standard legend to the side by adding a little bar chart to denote the number of observations in each bin (for this example, I took a screenshot of the original and added the bar chart next to the legend).

Yes, all of these approaches take up more room on the page or screen, but you’ll do your user or reader a great service.
As Monmonier writes, “classification introduces the risk of a mapped pattern that distorts spatial trends. Arbitrary selection of breaks between categories might mask a clear coherent trend with a needlessly fragmented map or oversimplify a meaningful intricate pattern with an excessively smoothed view.”
As content- and map-creators, we must be careful with how we visualize our geographic data and take care to use colors and bins that make sense.
Note: A huge thanks to Aaron Williams for writing (and teaching me) the R code to make some of these maps and especially the paired map-column chart pairs. You can find that code on Aaron’s Github page here. Another thanks to Brittany Fong for giving me some tips on how to create custom bins in Tableau, a task I found harder than I thought it would (and really should) be. Also, just as I was finishing this post, Lisa Charlotte Rost published this post from her new spot at Datawrapper; and she then uncovered this older post she had written on the topic a few years ago.






This is a fantastic discussion of something I’ve been thinking a lot about. Thanks!
Coincidentally, I previously implemented a version of the last histogram-type legend you mention
Also, I used a scrolling bar chart linked to a map in this data vis, as well:
http://docflows.unc.edu/
That’s based on an idea and implementation from Nadieh Bremer:
http://bl.ocks.org/nbremer/326fb6de768e85261bfd47aa1f497863
I’ve also been working on some other prototypes for compactly displaying distributions with legends, e.g., the attached. Related, I also like the idea of letting users adjust the bins themselves, especially for interactive data vis on large, varied datasets where programmatic selection of bins can often fail.
Attached image:
The link to Aaron’s Github repo of code for the charts does not work. I’m unable to find a public repo on his site with this code. Would you publish an updated link?
Hi David,
The link works for me. Be sure you’re signed into Github when you click on the link.
Thanks,
Jon
Thanks for the fast response!
If you see the repo when signed in to GitHub, then Aaron has not made that repository public but has instead only shared it with you. It’s definitely not accessible to the public (both logged in and not, tested on multiple browsers & systems). Aaron will need to make the repo public so that others can see it.
He just opened it up (and apologized for forgetting). Let me know if it doesn’t work.
Thanks again,
Jon
Diving further into the story, I noticed the link to the podcast with Mark Monmonier has a “mailto:” prefixed to it somehow. Once removed, it worked for me.
Attached image:
Thanks, that’s been fixed.
Good point.
But you haven’t escaped the problem even in the article itself.
According to definition text of percentage change column in “percentage change between the ranked states” table a formula for its value should be: ((“obj val” – “subj val”) / (“obj val”)) * 100. As it should tell how much “subject”(current table row, CHIP value) differs(less than) from “object”(previous table row). Another way it’s confusing and even misleading.
Although, if you want to keep a current formula you should move percentage column records one row up (keeping value references). So it tells how much “subj” is more than “obj”.
Okay, sure, but this is a minor point and I don’t see how I “haven’t escaped the problem” by calculating it in this way. Shifting the bars up one slot or reversing the calculation of percent change doesn’t change the basic story. Saying it’s misleading is overselling this critique, I think.