This is a guest post from David Napoli, a BI & Analytics Director (and recovering rocket scientist) who has worked as lead actuary, statistician, and headed up analytics departments for several healthcare organizations over the last 20 years.
In a couple of posts on this site, Jon wrote a step-by-step guide on how to construct static and interactive Tile Grid Maps in Excel. I’ve taken this a bit further and created a Hexagon Tile Map in Excel. Now, if at all possible, do yourself a favor and write up the steps you took in developing anything that is even remotely innovative … which I wish I would have done in this instance, since there unfortunately has been in excess of five months since I initially put this demonstration file together. I’ve included the Excel file for your use and am happy to answer follow-up questions or suggestions in the comment boxes below.
The basic premise of the method to develop a hexagon tile map in Excel is a scatterplot with a custom hexagon shape – custom in the sense I used the Shape tool within Excel to draw a hexagon of my own liking.
The data for the map displayed in the file can be found in the worksheet “Data” (yeah, I go out on a limb in naming my sheets), and the shape used in the tile map can be found in – you guessed it – the “Shape” worksheet. The guts can all be found in the “Work” sheet that the file opens up to, and the chart itself resides in the “Grid Map” sheet. All of the data series that are either the precursors to what is displayed or are the actual data series for the scatterplot can be found in the columns A through T on the “Work” sheet.
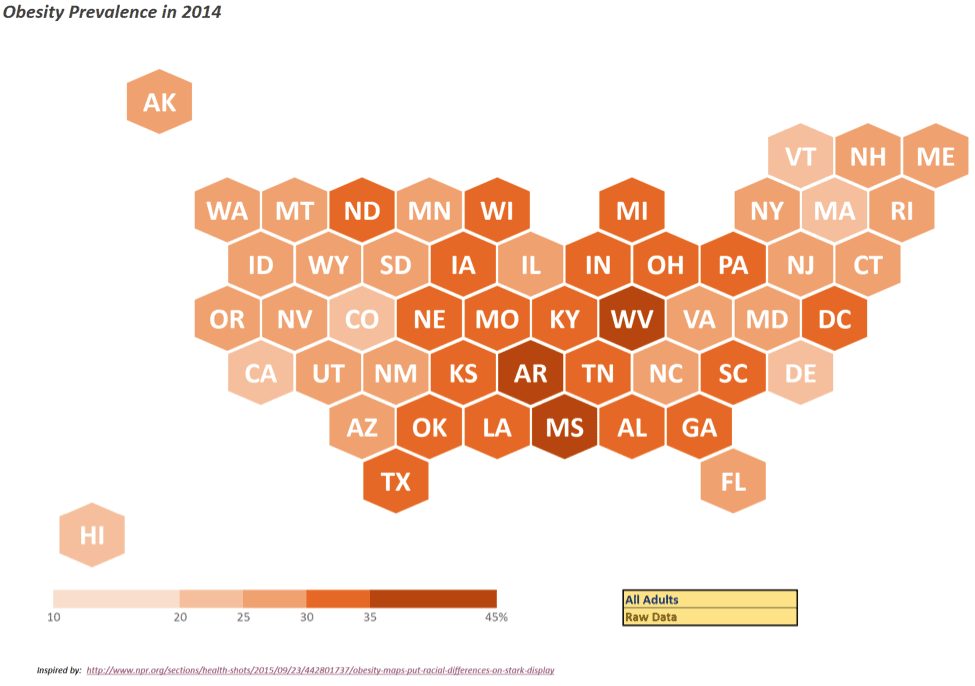
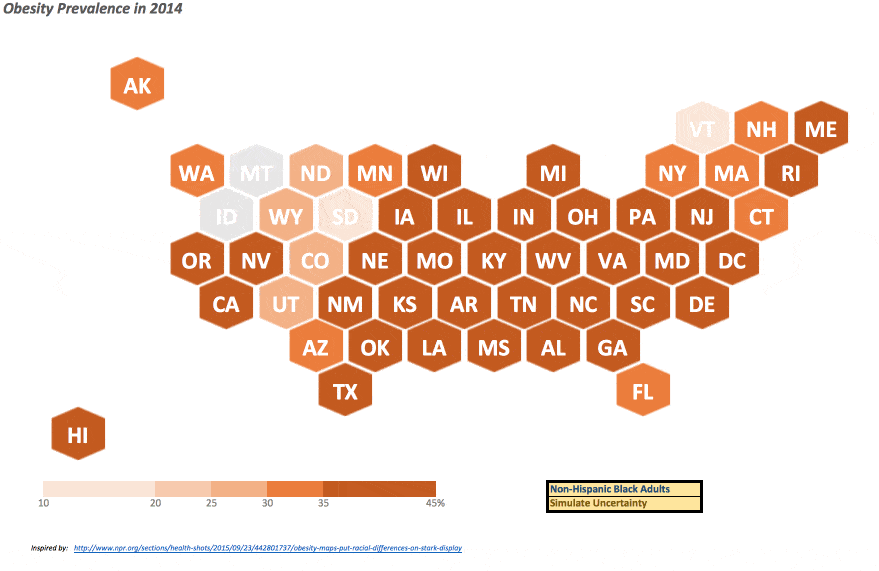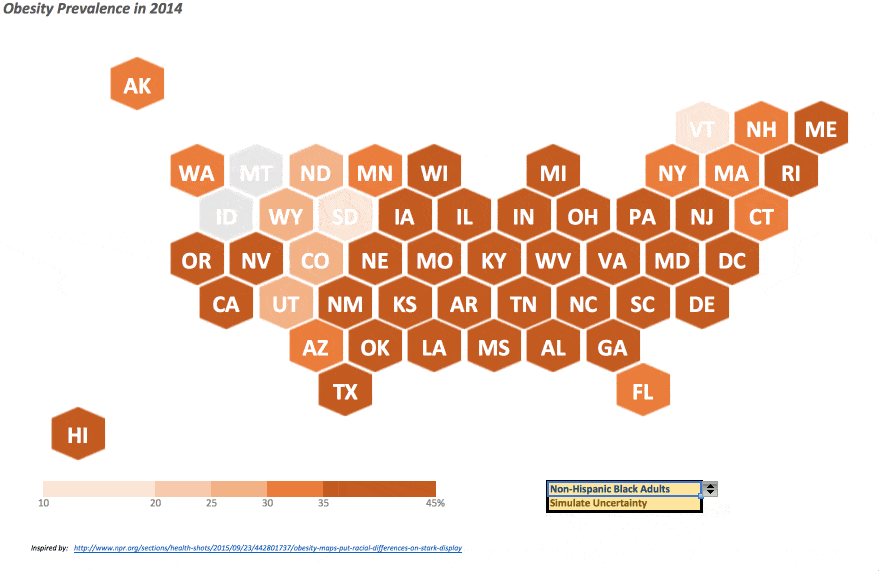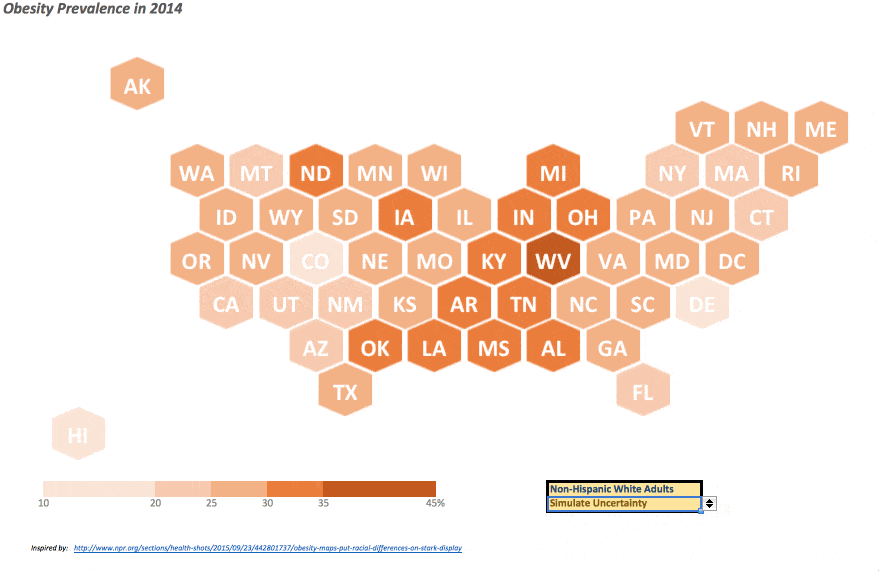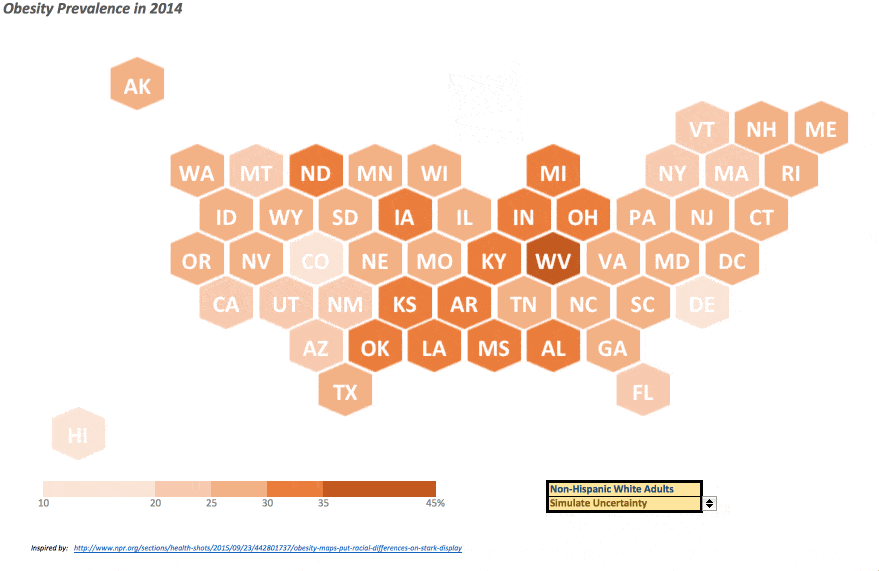
These data are (yes, plural – I went there) dichotomized into five distinct (color) ranges, exactly mirroring what was performed in this NPR article; a sixth category is included if data was not available for a given state. Confidence intervals on the prevalence statistics are also included, and I discuss how these were approached below.
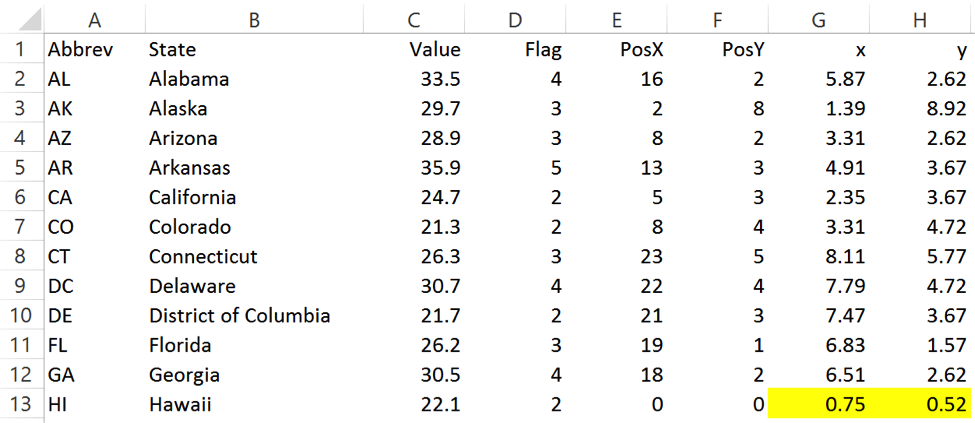
Each state’s data value are shown in column C, and are then placed into categories in column D. Each state is given a “PosX” and “PosY” value to position it appropriately on the map (and you thought those geography lessons would never come in handy!). One state acts as a reference for all other states – meaning, its position is fixed, and all others are relative to its X-Y position. As Hawaii is closest to the original on a scatterplot, it is the reference state and its X-Y pairing is hard-coded in the yellow cells in columns G and H.
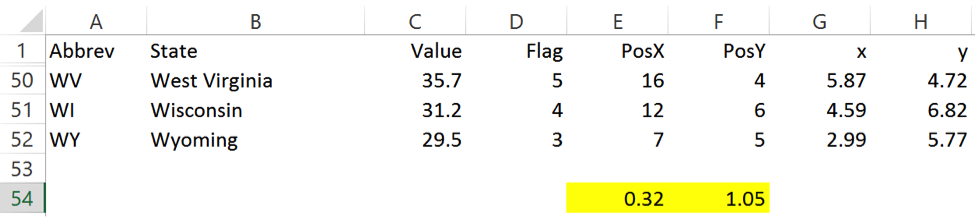
In order to handle different versions of Excel and displays properly, a “multiplier” is used – you can find these in cells E54 and F54 (highlighted in yellow in the image) – to obtain the correct spacing between the hexagon state shapes. The resulting values can be found in columns G and H. You will probably need to play around with these values in order to get the map to display with spacing between tiles that meets your liking.
Columns I through T contain the X-Y pairings for all of the possible data series, starting with if no data was available (“x-off” and “y-off”), then proceeding through the data range from low to high (“x-1” and “y-1” through “x-5” and “y-5”).

The formulae for the X-Y pairings determine if the flag value in column D matches the corresponding data series, and if so, the X-Y pairing values are displayed; otherwise, “#N/A” is returned to hide those specific data series on the scatterplot (this is actually a feature of using #N/A, not 0 or a missing value). These columns are the meat of what is displayed, but there are a few setup steps that needed to be performed before it all works. I am not absolutely certain these steps need be performed exactly as I delineate – I have not set aside time to test other methods – but they worked, so I describe them here.
Once I had all of the X-Y column pairings set up, I entered the X-Y values found in columns G and H for all of the data series columns, one data series at a time, so all of the states would show on the map. With that data series displayed, I changed the marker type to the hexagon shape found on the “Shape” sheet – making a copy of it and changing the fill color to the color corresponding to the category of the data series and inserting the picture from the clipboard as seen in the dialog box below (this is in Excel 2016, so your options may differ).
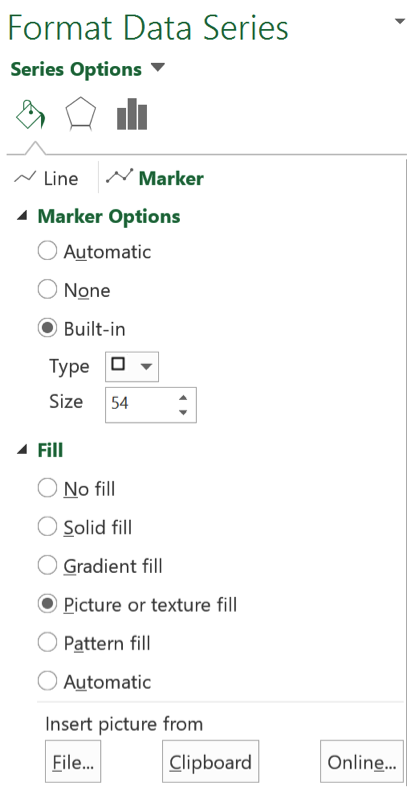
The next step turned out to be a bit involved, so I will do my best to explain…
I initially set the data labels for each series by assigning the state abbreviation range (found in column A) using the “Value From Cells” option available in Excel 2013/2016. This method, however, led to an issue when the file was saved/closed, and then reopened, where certain labels disappeared when different values were displayed in the chart. My first attempt to solve this was using VBA, which did work, but it resulted in a more complex file than may be desired by others.
There are two alternative methods that avoid using VBA:
- Manually label each data point; or
- Utilize one of the freely available Excel data labeler add-ins, such as The XY Chart Labeler.
In any case, I essentially mimicked (1) within VBA: I created a loop that labeled every data point, and then looped over all data series (you can download a text file with the VBA code here). And in case you are wondering, fewer or greater number of categories can be accommodated by adding/deleting columns and following these steps to add to the scatterplot, if needed.
Once all of the scatterplot setup steps have been performed and the X-Y pairings formulae have been readied, the hexagon map is ready to view. For this file, however, I added a few additional features to capture some of the data nuances found in the original NPR article.
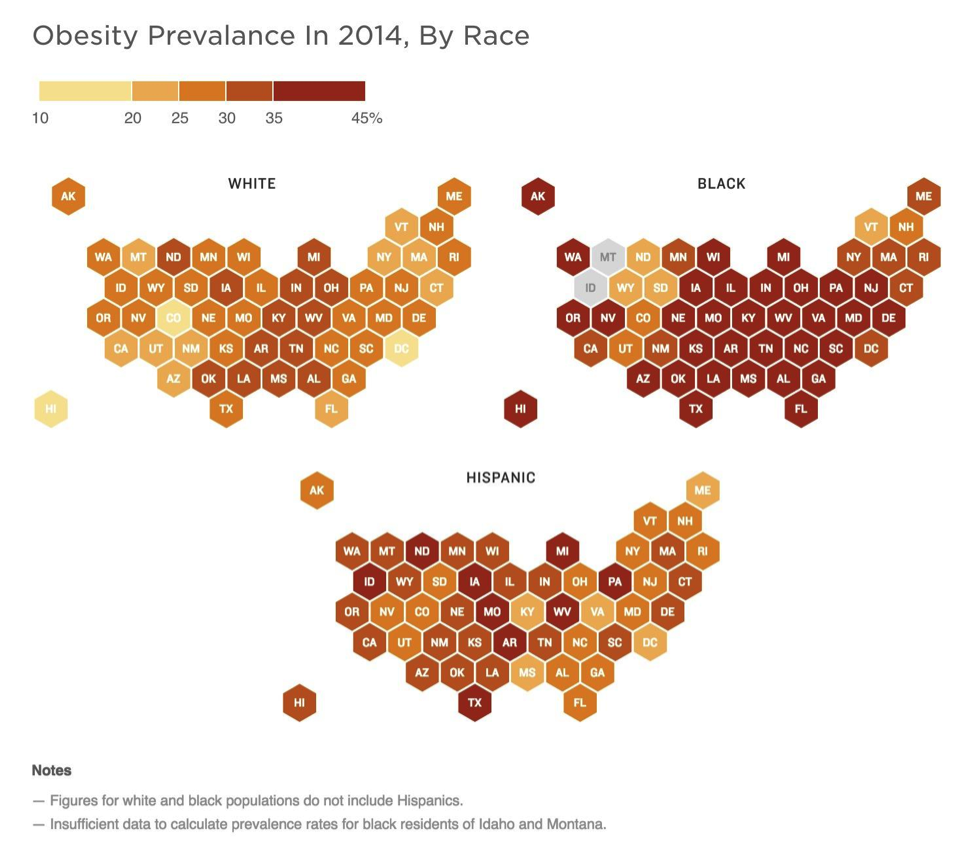
The NPR article touches on the racial differences in diabetes prevalence throughout the US, I’ve included a drop-down menu so the user can change which race she wants to display. A formula on the “Data” worksheet indexes the selection to return the appropriate value. Also, as confidence intervals on the prevalence data was available – and I am a staunch supporter of displaying and informing on the underlying uncertainty – the ability to show said uncertainty in these data can be performed by selecting “Simulate Uncertainty” in the corresponding drop-down. Hitting F9 (the function key, not the cell) or “⌘ plus =” on a Mac will perform a new simulation within the listed confidence interval for each state, so you can see how variable (or not) certain states and/or regions may indeed be in their diabetes prevalence.
This was certainly a fun project to put together, and I am absolutely confident this is not the only way to approach this nor the most efficient/innovate method, but given the popularity of this method and some recent efforts by others – such as the great work by Jon (twice!) – coupled with a snowstorm here last weekend, I was finally able to set aside some time to put thoughts to electrons and share this effort with whomever may be interested.
Thoughts, comments, and all their brethren are more than welcomed.






Excellent post. I was checking constantly this blog and I’m impressed!
Very helpful information particularly the last
part 🙂 I care for such info much. I was looking for this particular information for a very long time.
Thank you and best of luck.
That was incredibly creative, thanks! I combined the hex-grid operations of Amit Patel (Red Blob Games) with your display technique to create a hex-grid chart. Not sure yet what I’ll do with it… Annoying that Excel doesn’t provide a function to label data points automatically.
Attached image:
excellent !!!!
Hi – I’m hoping to change the colors of this using your template, but I can’t seem to figure it out. Would you be able to point me in the right direction?
On the “Shape” worksheet tab, select the hexagon and then “Shape Format” from the menu (I am currently using Excel 2019, so menu options may differ depending on what version of Excel you have access to) … from there, select “Shape Fill” within the “Shape Styles” section to change the color.
From there, copy the newly colored shape, go to the “Grid Map” worksheet tab and select the series of interest you want to change the color of (you can single click on one of the hexagons of the color you want to change to select that specific series or select the entire chart, go to the “Format” menu, then select the series of interest from the drop down menu w/in the “Current Selection” section), then just paste (CTRL or CMD V, depending on PC or Mac) the new color hexagon you copied.
Thank you so much!
FYI, when I downloaded the excel file, under the Work tab, it looks like the abbreviations for DC and DE are flipped? Thanks for this helpful post!